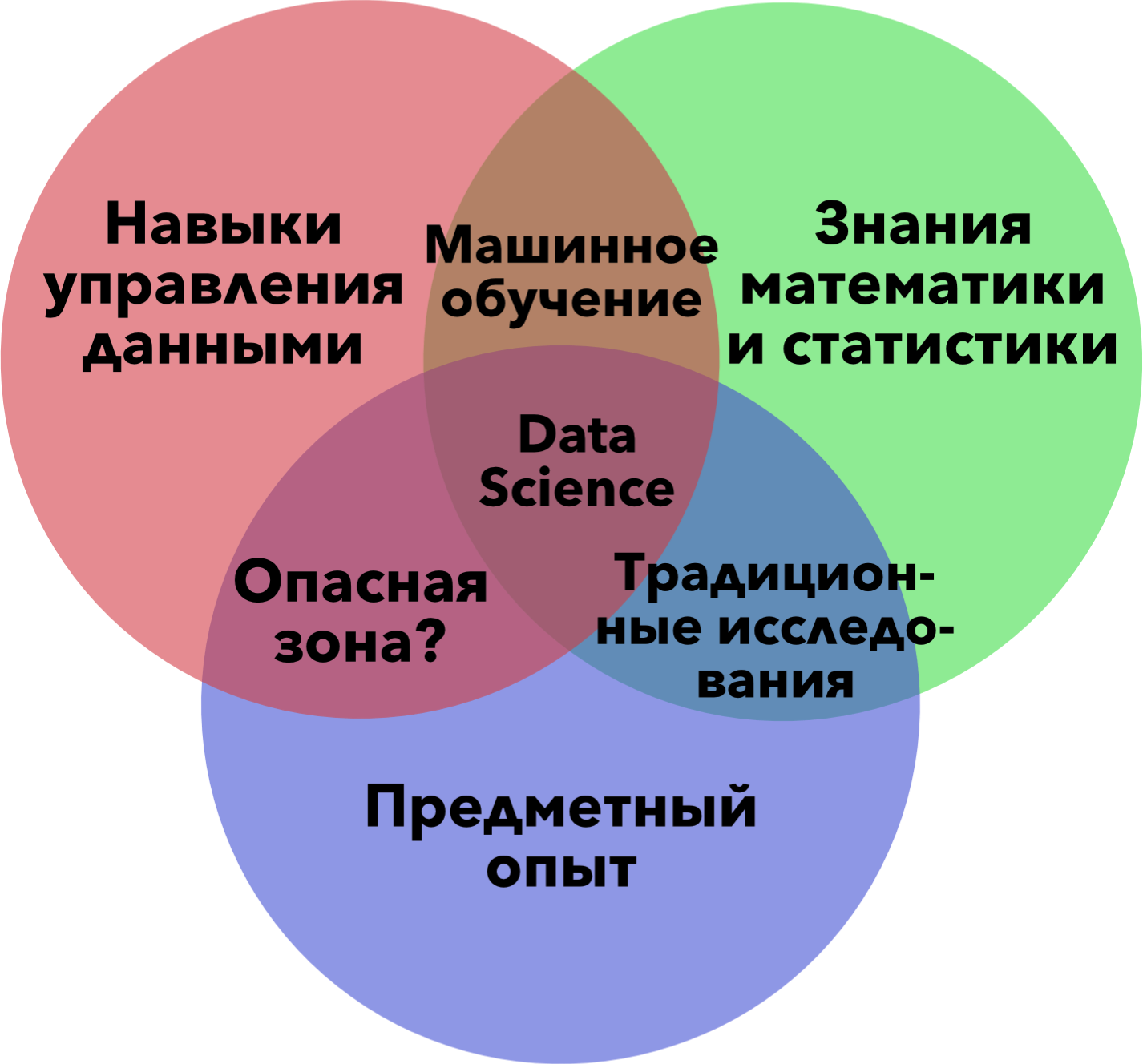
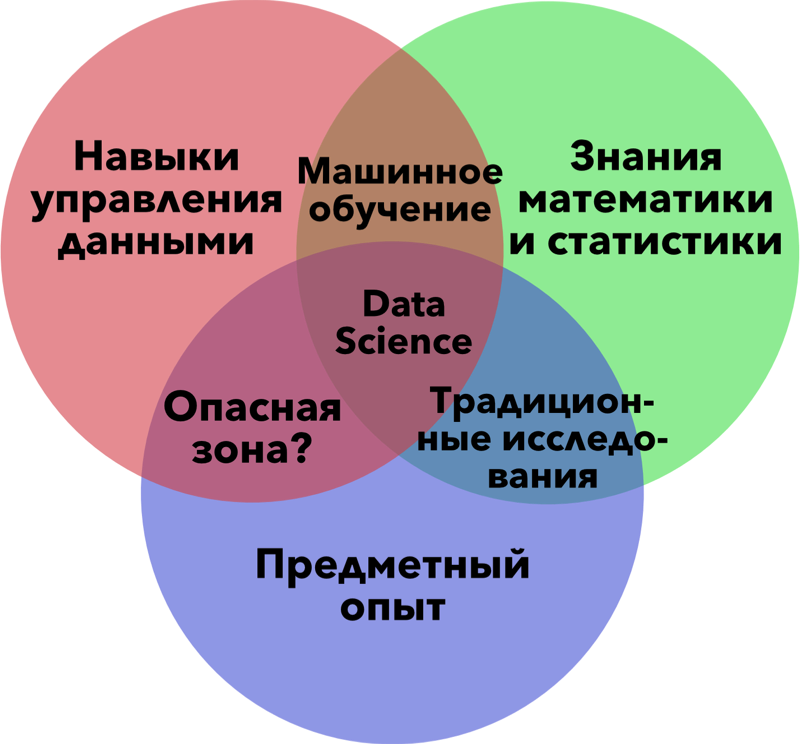
Ниже представлена известная многим диаграмма Дрю Конвея, призванная прояснить что такое Data Science. Несмотря на то, что в целом она справляется с поставленной задачей, есть ряд моментов, которые следует уточнить. В этой заметке я хочу коснуться двух - так называемой "опасной зоны" и самой сути Data Science.
"Опасная зона" является опасной (по мнению Дрю) поскольку люди, попадающие в нее, знают достаточно много в сфере программирования и своей предметной области, но слабо знакомы со статистикой. Это делает людей в "опасной зоне" опасными - статистический анализ может быть проведен неправильно со всеми вытекающими последствиями. На первый взгляд звучит правдиво. Но недавно я столкнулся с двумя примерами, которые заставили меня посмотреть на "опасную зону" с другой стороны. Первый я встретил в онлайн курсе "Техники и понятия больших данных" Бартона Полсона. Так, он говорит о парсинге естественного языка и дальнейшем подсчете частоты употребления тех или иных слов. И это не только область "опасной зоны". Это еще и область работы с Big Data. Второй пример связан с моим недавним опытом объединения массивов социологического мониторинга "Украинское общество". С 2006 года никто не занимался объединением массивов, а само исследование продолжали проводить - в 2008, 2010, 2012 и 2014 годах. Ну и "как у нас принято" в полученных массивах были несоответствия и по языку, и по меткам значений, и по именам переменных, что превратило их объединение из рутинной задачи в весьма трудоемкую деятельность. Очень пригодился R, начиная от переименования переменных и заканчивая расчетом индексов. И нельзя сказать, что здесь очень нужны были знания статистики, а вот эмпирической социологии - да. Поэтому такую деятельность логичнее отнести именно к "опасной зоне", которая собственно является скорее зоной комплексного управления данными (или может многоуровневого управления). Исходя из такой интерпретации "опасной зоны" можно по иному взглянуть и на Data Science. Одномоментная необходимость в трех основных элементах (управление данными, статистика, предметный опыт) является скорее идеализацией, чем хорошим описанием реального положения дел. Data Science всегда конкретна, то есть не является фундаментальной наукой (и не станет ею). Более того, скорее это просто набор навыков и техник, которые могут пригодиться в различных ситуациях при работе с данными различной природы. Используя такой подход навыки управления данными, знание статистики и предметный опыт составляют не Data Science, а Data Toolkit.