Алгоритм сравнения социально-демографических групп: на примере установок на гражданскую активность
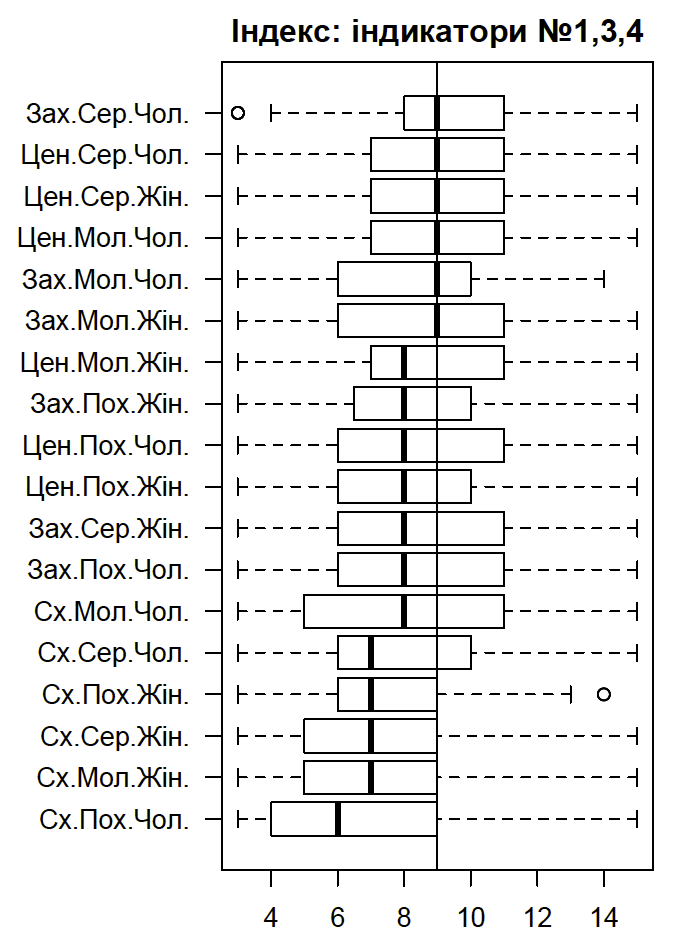
Цель визуализации - это, прежде всего, комплексное (и, как я надеюсь, интуитивно понятное) описание различий между набором социально-демографических групп, а не проверка влияния ряда факторов на независимую переменную.
В качестве параметра, подлежащего сравнению, использован индекс построенный на основании следующих индикаторов:
- Мне все равно какая будет власть, только бы не стало хуже
- Я свой выбор давно уже сделал, поэтому не хочу принимать
участие в нынешней политической жизни - Какой смысл бороться за свои права, если власть
своими действиями откровенно их игнорирует
Диапазон возможных значений от 3 до 15, где меньшие значения говорят о более пассивных установках, а большие - о более активных.
Представленный подход носит универсальный характер, т.е. он не привязан к этой конкретной теме и его легко реализовать для других статистических описаний (особенно учитывая, что он реализовано для непараметрических данных).
В этой заметке я сосредоточился на технической реализации, поэтому будет неудивительно, если у Вас возникнут вопросы и критические заменчания.
Анализ данных проведен на массиве данных социологического мониторинга «Украинское общество» 2016 года (Институт социологии НАН Украина).
Для анализа и визуализации использован язык программирования R.
Анализ вопросов с возможностью множественного выбора в R
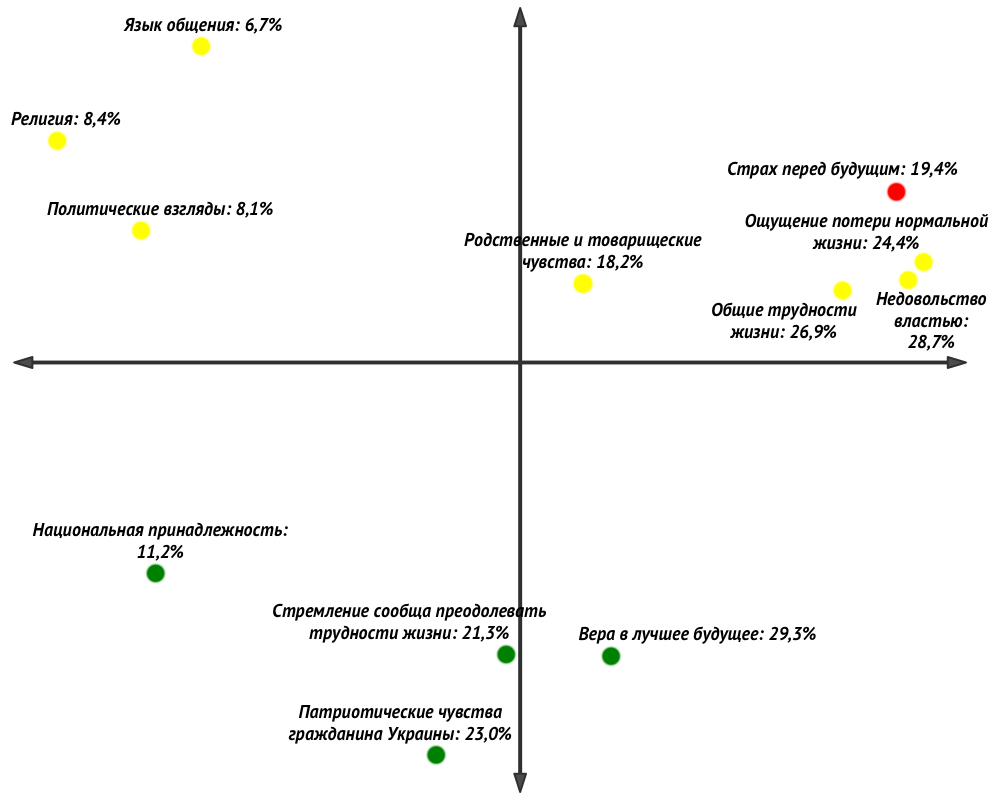
По Вашему мнению, что сегодня объединяет людей в украинском обществе? (Отметьте все подходящие ответы)
Поскольку отмечать можно было все подходящие ответы, то детальный анализ не такой простой как может показаться на первый взгляд. Ну и решил я поковыряться в этом всем с помощью R. Сначала стал придумывать как добраться до всех комбинаций, существующих в данных… и в принципе добрался, но не могу сказать, что это мне очень сильно помогло. Но было забавно. Поэтому ниже в статье мои скромные скрипты, если вдруг кто-то решит таким же заниматься. Допускаю, что в определенных случаях они могут быть вполне полезными (например, при ограничениях на количество выбираемых альтернатив).
P.s. - когда я понял что ковыряние в имеющихся комбинациях не очень перспективно, то обратился к старому доброму многомерному шкалированию (эти команды тоже есть). Результат на рисунке. Проценты показывают как часто выбиралась альтернатива. Цвет точек показывает установки на гражданскую активность. Зеленые точки показывают мотивы, выбираемые респондентами, среди которых повышенная представленность установок на гражданскую активность, желтые – с обычной представленностью, красная – с пониженной представленностью. Интерпретации получаются весьма интересные =)
Время, деньги и R

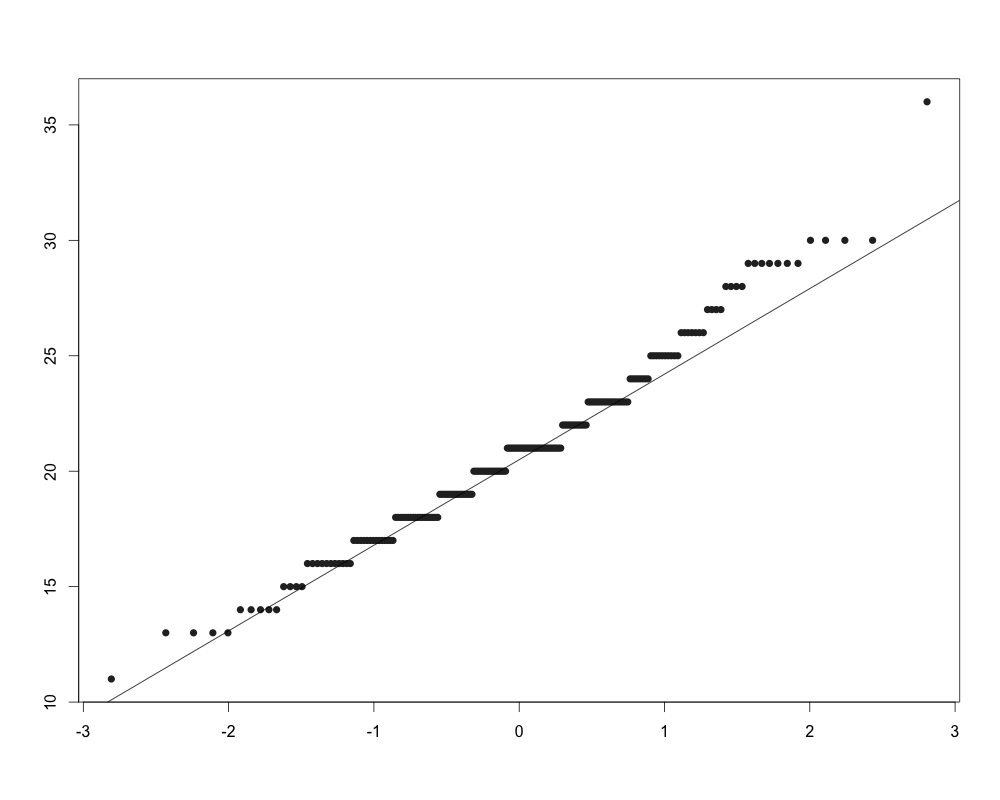
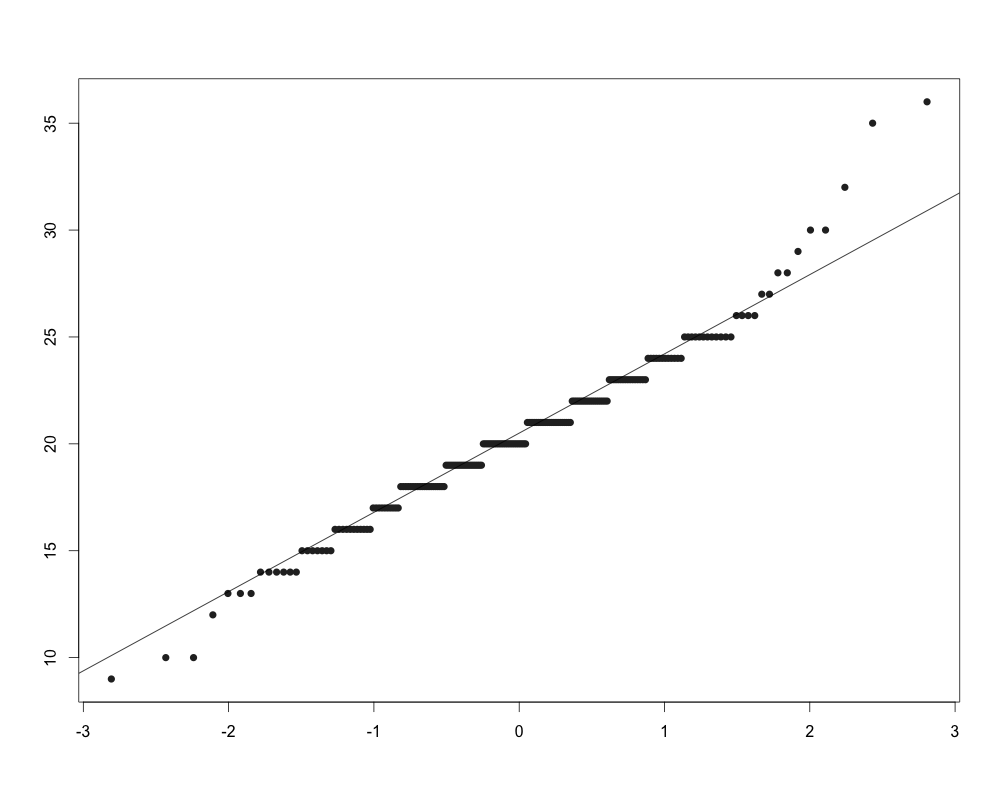
Критерий Шапиро-Уилка: выборки и статистическая значимость
Киев
Львов
Модификация социологических данных средствами R

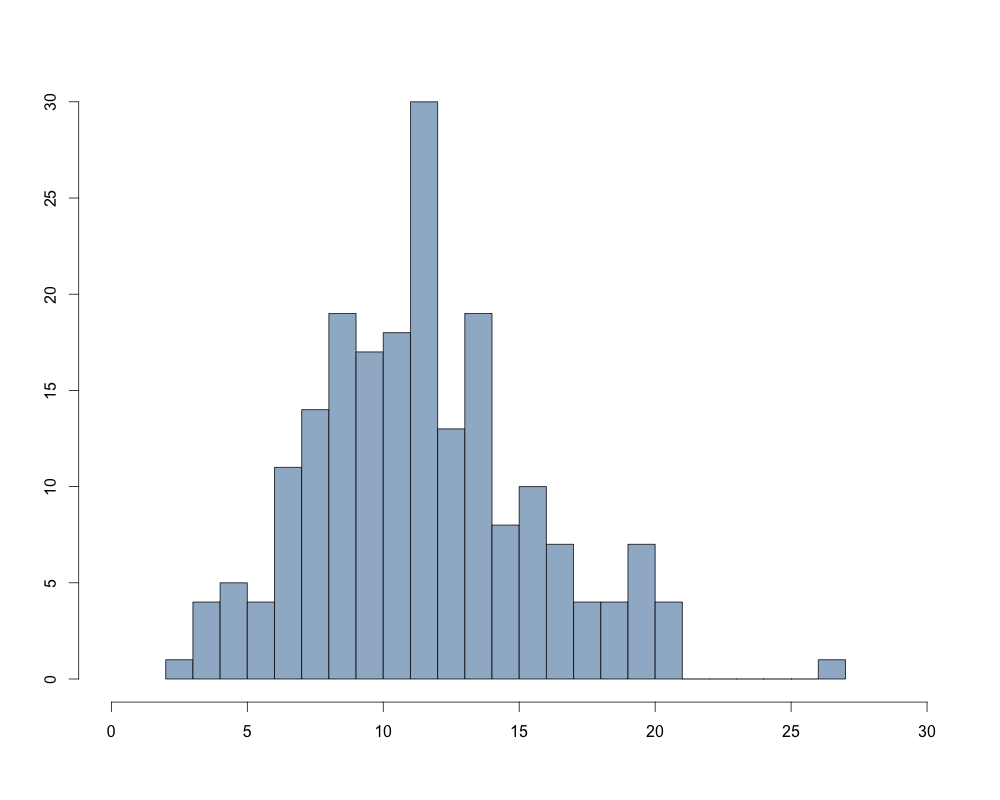
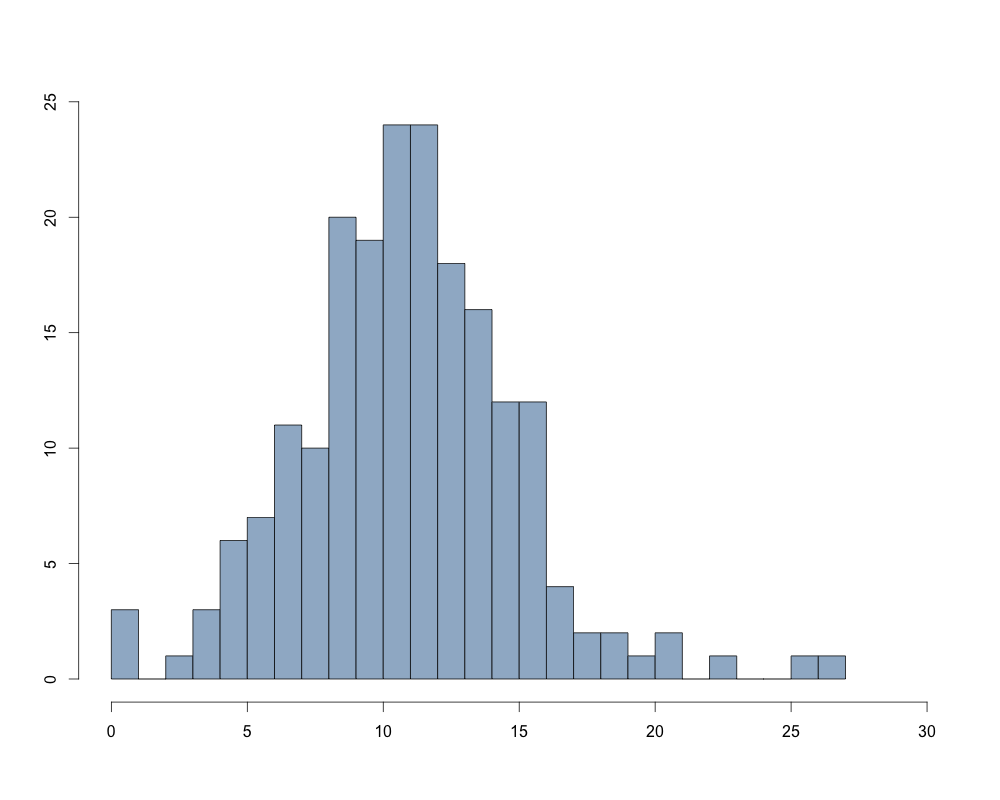
В случае использования числовой переменной с большим диапазоном возможных значений, следует проверить ее на наличие «выбросов» - нетипично больших или малых значений. Для визуализации последних можно использовать функцию boxplot(), позволяющую построить диаграмму размахов. В качестве данных создадим вектор значений «salary» на основании переменной «l3», исключив из нее респондентов без доходов и использовав только тех респондентов, которые были опрошены в рамках последнего этапа исследования, то есть в 2014 году.
finalUSind$salary <- NA
indexes <- which(finalUSind$l3 > 0 & finalUSind$year == 2014)
finalUSind$salary[indexes] <- finalUSind$l3[indexes]
boxplot(salary, horizontal = T, las = 1, col = "slategray3",
outpch = 16, outcol = "slategray3")
Полученная диаграмма (см. рис.1) показывает нижнюю и верхнюю границы «выбросов», квартили, медиану и сами «выбросы» (они отмечены точками). Читать дальше...
Логический контроль (чистка) данных

Контроль массива данных также называют «чисткой массива». Последнее определение чаще используется в кругу отечественных исследователей, поэтому далее мы будем использовать именно его. Это крайне важный этап управления данными, который позволяет:
- определить ошибки ввода операторами;
- привести массив к удобному формату для дальнейшей работы с ним;
- найти анкеты, которые могли быть фальсифицированы.
Работа с пропущенными данными: теория и практика

Обработка пропущенных значений является достаточно развитой исследовательской областью с общепринятой терминологией и множеством решений для различных дисциплин и конкретных исследований. С попыткой широкого обобщения основ обработки пропущенных данных в социальных науках можно ознакомиться, например, в работе Даниэля Ньюмана [Newman, 2014]. В рамках же данной статьи мы обратимся к главным понятиям этой теории, а также основным методам решения проблемы пропущенных значений.
Виды пропусков
Принято выделять три вида пропусков - полностью случайные, случайные и неслучайные пропуски (данная терминология ведет свое начало от известной работы Дональда Рубина [Rubin, 1976]). Полностью случайные пропуски (ПСП-допущение) имеют место в тех случаях, когда подвыборка имеющихся значений по переменной(-ым), подлежащей изучению, по-прежнему является моделью генеральной совокупности. Примером может служить случай, когда пропуски по некоторой переменной (например, политические предпочтения) не зависят от значений переменных-предикторов (например, пол, возраст, регион проживания и т.д.), а также от значений самих пропусков (например, не возникает ситуации, когда респонденты с определенной политической позицией чаще других не дают ответа на соответствующий вопрос). Выбор модели полностью случайных пропусков - единственное допущение, которое можно проверить эмпирически. Что касается случайных и неслучайных пропусков, соответствующие допущения невозможно проверить на основании имеющегося массива.
При случайных пропусках (СП-допущение) их значения зависят от значений переменных-предикторов и не зависят от собственных значений пропусков. Так, если пропуски в ответах на вопрос о политических предпочтениях чаще встречаются среди людей старшего возраста (но внутри этой группы они распределены случайно), то речь идет о случайных пропусках. В этом случае возникает вероятность смещения результатов оценивания параметров по выборке в целом (если значение по соответствующей подгруппе отличается от общего среднего).
Если же вероятность пропусков по определенным переменным зависит от величины самих пропущенных значений по этим переменным, то говорят о неслучайных пропусках (НП-допущение). Например, люди с левыми политическими взглядами с меньшей вероятностью склонны сообщать соответствующую информацию. Такие пропуски вносят систематические ошибки в результаты анализа. Читать дальше...
Взвешивание данных таблиц сопреженности в R

Новости об R от белорусов

Статистические выводы: таблицы сопряженности и сравнение средних

В предыдущих двух главах было рассмотрено построение частотных таблиц (в том числе и таблиц сопряженности), а также средних значений, как методы описательной статистики. Как известно эти методы позволяют делать и статистические выводы. Последним и посвящена эта глава.
В случае таблиц сопряженности предварительно необходимо создать соответствующие объекты и уже к ним применять статистические критерии. В случае же сравнения средних значений работа может вестись как с массивом данных напрямую, так и со специально созданными векторами.
Читать дальше...
Описательные статистики: средние значения

Вобщем прикоснемся к прекрасному - обобщению данных с помощью средних значений. Самый простой способ заключается в использовании функции summary(). Она может быть применена как к вектору, так и к фрейму данных (в последнем случае обобщенные данные будут выведены для всех переменных массива). В зависимости от того, является ли переменная фактором или просто чиcловым вектором, выведенные результаты будут соответственно или в виде одномерного частотного распределения, или в виде набора показателей (минимальное значение, первый квартиль, медиана, среднее, третий квартиль, максимальное значение). Для примера я использую массив с показателями Freedom House и UNDP по всем странам мира.
Чтобы не загромождать текст, выведу сводку данных только для трех переменных массива - статуса свободы, ожидаемой продолжительности жизни и среднего количества лет обучения в стране: Читать дальше...
Data Science: набор интегрированных спецкурсов на курсере
Вот такой ништяк можно получить от университета Джона Хопкинса:
Но стоить это будет 490 баксов + необходимо успешно пройти курсы. Вернее сначала вы можете успешно пройти курсы, а уже потом заплатить за сертификаты, при желании, конечно. Следовательно, все курсы абсолютно бесплатны. Набор тем действительно исчерпывающий. Остаются вопросы по отдельным лекторам. Например, Роджер Пэнг, как по мне, какой-то унылый. Но ценность информации это не уменьшает. Подробности здесь.
Скрипт для согласования концептов: 1 и 0

Чтобы хоть как-то объяснить сущность этих матриц, приведу цитату (с остальным можно ознакомиться перейдя по ссылке выше): "... результаты (...) представляются в виде квадратной таблицы (матрицы), которая имеет количество строк и столбцов равное количеству утверждений. Все значения этой матрицы могут принимать только два значения – «0» или «1». Единица является показателем того, что утверждения по строке и столбцу размещаются (...) в одной группе, в то время как ноль указывает на то, что они размещаются в разных группах". Читать дальше...
Описательные статистики: одномерные и многомерные частотные распределения

Объект данных таблица создается с помощью функции table(), которая может принимать в качестве аргумента различные массивы данных (например, векторы, множества, фреймы). Эта функция является базовой при построении как одномерных, так и многомерных таблиц сопряженности. К полученному в результате ее использования объекту применяются другие функции, позволяющие строить таблицы модифицированные под потребности исследователя. Читать дальше...
Рекурсия и изменение глобальных объектов
Основы программирования: авторские функции

Вместе с тем, возникают и ситуации, когда необходимо написать такой программный код, который бы решал одну и ту же задачу, возникающую часто и требующую учета изменяющихся ключевых данных. По этой причине, в процессе работы можно применять не только уже имеющиеся функции, но и создавать свои собственные. Такие авторские функции позволяют использовать уже имеющиеся в R функции, условные операторы, циклы, списки и многое другое. Для многих языков программирование функциональное программирование является одной из основ. В случае R (если мы говорим про анализ данных) многие задачи уже реализованы как в базовой версии, так и виде расширений. Несмотря на это, функциональное программирование в R также является важным дополнением, существенно расширяющим возможности исследователя. Читать дальше...
Основы программирования: списки

Именно списки очень удобно использовать в работе циклов - добавление новых элементов будет идти не по пути перезаписи списка, а по пути его расширения. Благодаря использованию циклов, условных операторов и списков открываются широкие возможности решения творческих задач как в рамках программирования в целом, так и в рамках анализа данных в частности. Читать дальше...
Основы программирования: условные операторы

R-скрипка для анализа данных онлайн

Для примера я создал в R-fiddle страницы с кодом из предыдущей статьи по циклам: шахматы, хоббиты.
Основы программирования: циклы
Согласно Wiki, "цикл — разновидность управляющей конструкции в высокоуровневых языках программирования, предназначенная для организации многократного исполнения набора инструкций... Последовательность инструкций, предназначенная для многократного исполнения, называется телом цикла. Единичное выполнение тела цикла называется итерацией. Выражение определяющее, будет в очередной раз выполняться итерация, или цикл завершится, называется условием выхода или условием окончания цикла (либо условием продолжения в зависимости от того, как интерпретируется его истинность — как признак необходимости завершения или продолжения цикла). Переменная, хранящая текущий номер итерации, называется счётчиком итераций цикла или просто счётчиком цикла". Читать дальше...
Тестовая версия RStudio для OS X Mavericks
Хорошие новости для пользователей RStudio на Маке. Вчера вышла новая тестовая версия для OS X Mavericks (10.9). Старая версия под новую ось притормаживала. Качать отсюда:
http://www.rstudio.com/ide/download/preview
Управление данными: работа с переменными

Довольно часто подготовка к анализу может занимать намного больше времени, чем сам анализ. Поэтому проблемы управления данными занимают важное место в аналитическом процессе. И поскольку R является не только средой статистической обработки данных, но и языком программирования, он предоставляет множество инструментов по управлению данными.
В сегодняшней статье я хочу коснуться только части из них, а именно: вычисления новых переменных, перекодировки имеющихся, работы с пропущенными значениями, "склеивания" массивов, выборки переменных и наблюдений. Читать дальше...
Работа с переменными-факторами. Влияние типа переменной на особенности анализа
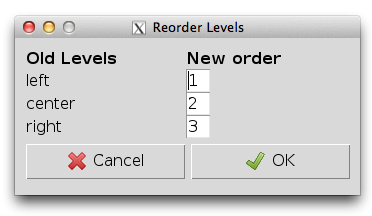
R выдвигает достаточно жесткие требования к организации данных. В частности это касается категориальных (номинальных и порядковых) переменных, которые называются в R факторами. В сегодняшней статье я коснусь особенностей создания факторов, ограничений, связанных с их обработкой, а также возможностей, предоставляемых R Commander при работе с ними. Текст статьи предполагает вашу осведомленность с типами переменных. Освежить соответствующие знания можно здесь, здесь и здесь.
R Commander - графический интерфейс пользователя для работы с R. Использование файлов R Script для организации работы
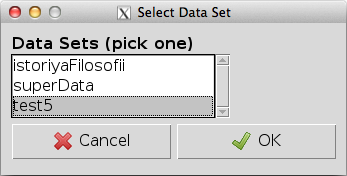
Одной из особенностей R является первоначальное отсутствие графического интерфейса пользователя, такого как, например, в SPSS. Вместе с тем, существуют расширения, позволяющие использовать авторские графические интерфейсы. Одним из наиболее популярных является R Commander. Он предоставляет широкие возможности для импорта и экспорта данных, использования основных методов анализа и построения графиков. Сегодняшняя статья посвящена именно ему.
Кроме того, я расскажу также об использовании файлов R Script, которые позволяют фиксировать аналитический процесс и в случае необходимости быстро осуществить его вновь.
Создание массива данных в R

Это первая из серии статей, посвященных основам использования R. Одной из их особенностей будет направленность на специфику социологического анализа. Следовательно те моменты, которые есть в R, но не касаются социологии я буду намерено опускать.
Как и в других средах анализа данных, в R можно открыть, создать или импортировать данные. Я остановлюсь на каждом из этих способов. А поскольку вопрос создания массива данных тесно связан с типами и структурами данных, постольку соответствующим темам также будет уделено внимание.
Среда статистических вычислений R: краткая история возникновения, преимущества и недостатки, текущее состояние использования

Прежде чем перейти к рассмотрению заявленных в названии статьи вопросов, хочется сказать о следующем. Отечественная социология демонстрирует удивительную инертность во многих вещах. Но если ситуацию с освоением качественного подхода можно объяснить историческими особенностями нашей социологии, то недостаток, а часто и отсутствие, внимания к современным разработкам в области количественного социологии не всегда легко понять. Исходя из этого, главная задача данной статьи - познакомить читателей с чрезвычайно продуктивной и популярной зарубежом средой статистической обработки, которая уже в обозримом будущем может составить конкуренцию таким известным в нашей социологии программам обработки данных как SPSS и ОСА.