Работа с переменными-факторами. Влияние типа переменной на особенности анализа
02/11/13 15:08 Относится к категории: Анализ данных | R
R выдвигает достаточно жесткие требования к организации данных. В частности это касается категориальных (номинальных и порядковых) переменных, которые называются в R факторами. В сегодняшней статье я коснусь особенностей создания факторов, ограничений, связанных с их обработкой, а также возможностей, предоставляемых R Commander при работе с ними. Текст статьи предполагает вашу осведомленность с типами переменных. Освежить соответствующие знания можно здесь, здесь и здесь.
Создание категориальных переменных (факторов) в R
Фактор в R представляет собой вектор значений, количество которых составляет k, где k - количество категорий переменной. Каждой из этих категорий соответствует текстовая метка, используемая при отображении значений фактора. По сути, факторы являются категориальными (номинальными и порядковыми, по другому - качественными) переменные. Они играют важную роль, поскольку являются в R группирующими переменными, которые используются для многих статистических методов, а также при построении диаграмм и интуитивно понятных таблиц.
Для создания фактора можно использовать как текстовый, так и числовой вектор (или переменную из фрейма данных). Для этого используется функция factor(). Основными аргументами этой функции являются следующие:
Фактор в R представляет собой вектор значений, количество которых составляет k, где k - количество категорий переменной. Каждой из этих категорий соответствует текстовая метка, используемая при отображении значений фактора. По сути, факторы являются категориальными (номинальными и порядковыми, по другому - качественными) переменные. Они играют важную роль, поскольку являются в R группирующими переменными, которые используются для многих статистических методов, а также при построении диаграмм и интуитивно понятных таблиц.
Для создания фактора можно использовать как текстовый, так и числовой вектор (или переменную из фрейма данных). Для этого используется функция factor(). Основными аргументами этой функции являются следующие:
vector или varName$dataFrame
levels = c(...)
order = TRUE (по умолчанию FALSE)
labels = c(...)
Первый аргумент просто задает объект, на основании которого создается фактор. Это может быть или вектор, или переменная во фрейме данных. Аргумент levels используется для задания порядка категорий фактора (фактически, для определения того порядка в котором они будут выводиться на экран). Если не задать этот аргумент, то категории будут выводиться по алфавиту. Если же необходимо создать упорядоченный фактор (порядковую переменную), следует установить аргумент order равным TRUE (или T). Аргумент labels используется в тех случаях, когда необходимо изменить демонстрируемые категории фактора. Он предназначен для числовых векторов или переменных, т.к. текстовые уже имеют наименование категорий.
Таким образом, возможны следующие [основные] ситуации при создании фактора:
| Заданные аргументы | Результат |
| vector | Неупорядоченный фактор (номинальная переменная); имена категорий - как они заданы в векторе/переменной, на основании которого создавался фактор; порядок представления категорий - алфавитный. |
| vector + labels | Неупорядоченный фактор (номинальная переменная); имена категорий заданы исследователем, т.е. не совпадают с именами в исходном векторе/переменных (для изменения числовых векторов/переменных); порядок представления категорий - алфавитный. |
| vector + levels + labels | Неупорядоченный фактор (номинальная переменная); имена категорий заданы исследователем, т.е. не совпадают с именами в исходном векторе/переменной (для изменения числовых векторов/переменных); порядок представления категорий также определен исследователем. |
| vector+ levels + order + labels | Упорядоченный фактор (порядковая переменная); имена категорий заданы исследователем, т.е. не совпадают с именами в исходном векторе/переменной (для изменения числовых векторов/переменных); порядок представления категорий также определен исследователем. |
Рассмотрим пример с созданием факторов:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | > someData <- data.frame() # создаем пустой фрейм данных
> fix(someData) # открываем форму для ввода значений, меняем имена и тип переменных и вводим данные (см.рис.1)
> summary(someData) # смотрим сводку по данным
gender politicalViews income
Min. :1.0 Length:12 Min. :250.0
1st Qu.:1.0 Class :character 1st Qu.:337.5
Median :1.5 Mode :character Median :425.0
Mean :1.5 Mean :477.5
3rd Qu.:2.0 3rd Qu.:662.5
Max. :2.0 Max. :800.0
> someData$gender <- factor(someData$gender) # преобразуем переменную "gender" в фактор
> someData$politicalViews <- factor(someData$politicalViews) # преобразуем переменную "politicalViews" в фактор
> summary(someData) # смотрим сводку по данным
gender politicalViews income
1:6 center:4 Min. :250.0
2:6 left :4 1st Qu.:337.5
right :4 Median :425.0
Mean :477.5
3rd Qu.:662.5
Max. :800.0
> someData$gender <- factor(someData$gender,labels=c("женщина","мужчина")) # указываем, что "1" - это женщина, а "2" - мужчина
> someData$politicalViews <- factor(someData$politicalViews,levels=c("left","center","right")) # меняем порядок выведения категорий для переменной о политических взглядах
> summary(someData) # смотрим сводку по данным
gender politicalViews income
женщина:6 left :4 Min. :250.0
мужчина:6 center:4 1st Qu.:337.5
right :4 Median :425.0
Mean :477.5
3rd Qu.:662.5
Max. :800.0
|
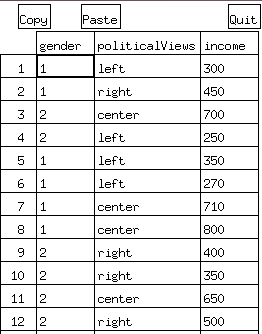
Как можно увидеть, после первой сводки данных (3 строка синтаксиса) результаты не являются удовлетворительными. Во-первый, по полу выводится информация как для метрической переменной, во-вторых, информация о политических взглядах вообще не обрабатывается (указывается только, что это текстовый вектор, а также приводится его длина).
После преобразования этих переменных в факторы ситуация меняется к лучшему, но все равно остаются моменты, которые необходимо поправить.
После преобразования этих переменных в факторы ситуация меняется к лучшему, но все равно остаются моменты, которые необходимо поправить.
Нужно указать, что единицами обозначаются женщины, а двойками - мужчины. Также следует переопределить порядок политических предпочтений так, чтобы центристские взгляды стояли посередине. Для политических взглядов можно изменить и параметр order. Но поскольку некоторым это может показаться сомнительным, я оставлю соответствующую переменную неупорядоченной.
В итоге, последняя сводка данных (строка 23) хорошо описывает все три переменные.
В итоге, последняя сводка данных (строка 23) хорошо описывает все три переменные.
Особенности статистической обработки факторов
Одна из сложностей, связанная с факторам в R, заключается в том, что к ним применимы только те функциональные возможности, которые не противоречат правилам обработки данных, принятым в статистике (и которые очень часто нарушаются в гуманитарных науках). Например, если переменная преобразована в фактор, то рассчитать для нее в R среднее значение уже не получится. Не получится применить и большинство других статистических методов (в то время как в SPSS все эти «невалидные» операции возможны).
Одна из сложностей, связанная с факторам в R, заключается в том, что к ним применимы только те функциональные возможности, которые не противоречат правилам обработки данных, принятым в статистике (и которые очень часто нарушаются в гуманитарных науках). Например, если переменная преобразована в фактор, то рассчитать для нее в R среднее значение уже не получится. Не получится применить и большинство других статистических методов (в то время как в SPSS все эти «невалидные» операции возможны).
Для решения этой проблемы можно использовать следующее. Во-первых, можно начать с фрейма данных, в котором все переменные являются числовыми (т.е. не являются факторами). Далее записать этот фрейм в новый и преобразовывать уже его. То есть, когда будет необходимость в «невалидном» анализе использовать первый массив, а когда в использовании факторов - второй. Во-вторых, можно использовать группу функций, преобразовывающих переменные-факторы в их изначальный вид. Для числового формата - это as.numeric():
31 32 33 34 35 36 37 38 39 40 41 42 | > testVector <- c(1,2,3,4,5,6,7,8,9,10) # создаем числовой вектор
> testVector <- factor(testVector) # преобразуем его в фактор
> mean(testVector) # пробуем (безрезультатно) найти среднее значение
[1] NA
Warning message:
In mean.default(testVector) :
argument is not numeric or logical: returning NA
> mean(as.numeric(testVector)) # находим среднее значение с временным преобразованием в числовой вектор
[1] 5.5
> testVector <- as.numeric(testVector) # опять делаем вектор числовым
> mean(testVector) # опять находим среднее
[1] 5.5
|
Использование R Commander
RC предоставляет достаточно широкие возможности для создания переменных факторов (многие из них выше мною даже не упомянуты). Здесь я охарактеризую их очень кратко.
Путь к соответствующим командам следующий: Данные => Работа с переменными => 5, 6, 7 или 8 пункт меню.
RC предоставляет достаточно широкие возможности для создания переменных факторов (многие из них выше мною даже не упомянуты). Здесь я охарактеризую их очень кратко.
Путь к соответствующим командам следующий: Данные => Работа с переменными => 5, 6, 7 или 8 пункт меню.
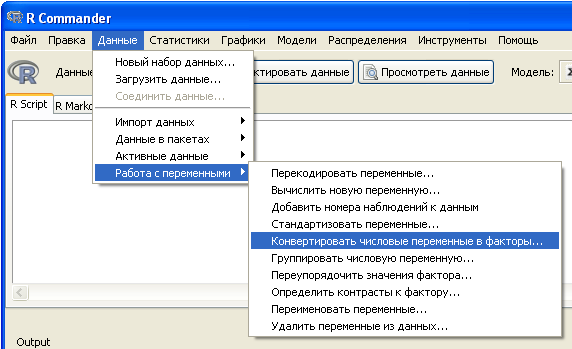
Опция "Конвертировать числовые переменные в факторы..." используется для создания фактора из числовой переменной (предположительно с небольшим количеством категорий).
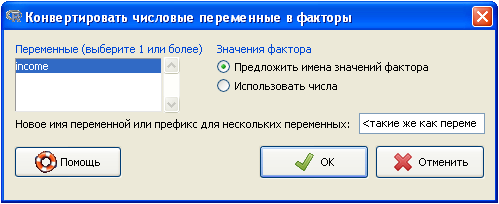
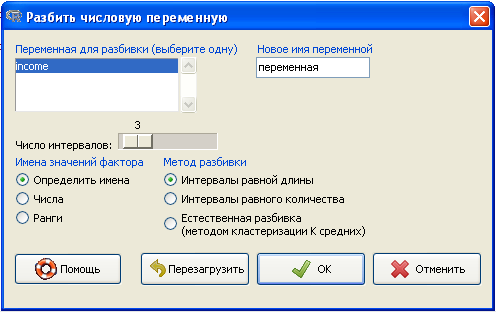
Опция "Группировать числовую переменную..." позволяет создать фактор на основании числовой переменной с большим количеством категорий. Способы разные, попробуйте их.
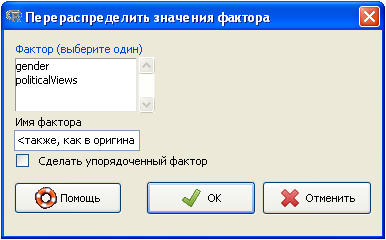
Опция "Переупорядочить значения фактора..." используется для переопределения порядка категорий уже имеющихся факторов.
С использованием последней оции сталкиваться не приходилось.
статью подготовил кандидат социологических наук Сергей Дембицкий
Вверх
blog comments powered by Disqus