Описательные статистики: средние значения
06/08/14 14:04 Относится к категории: Анализ данных | R

Вобщем прикоснемся к прекрасному - обобщению данных с помощью средних значений. Самый простой способ заключается в использовании функции summary(). Она может быть применена как к вектору, так и к фрейму данных (в последнем случае обобщенные данные будут выведены для всех переменных массива). В зависимости от того, является ли переменная фактором или просто чиcловым вектором, выведенные результаты будут соответственно или в виде одномерного частотного распределения, или в виде набора показателей (минимальное значение, первый квартиль, медиана, среднее, третий квартиль, максимальное значение). Для примера я использую массив с показателями Freedom House и UNDP по всем странам мира.
Чтобы не загромождать текст, выведу сводку данных только для трех переменных массива - статуса свободы, ожидаемой продолжительности жизни и среднего количества лет обучения в стране:
1 2 3 4 5 6 7 8 9 | > summary(forT[3:5])
freedom health education
свободная :87 Min. :48.10 Min. : 1.200
частично свободная:61 1st Qu.:64.90 1st Qu.: 5.300
несвободная :47 Median :73.20 Median : 8.000
NA's : 3 Mean :70.03 Mean : 7.687
3rd Qu.:76.80 3rd Qu.:10.100
Max. :89.50 Max. :13.300
NA's :5 NA's :13
|
Конечно же есть и единичные базовые функции для расчета мер центральной тенденции. Но они могут работать не совсем так, как мы ожидаем. Для примера рассмотрим функцию mean(). Если в качестве аргумента-объекта мы применим переменную массива, то получим следующее:
10 11 12 13 14 | > mean(forT[4],na.rm=T)
[1] NA
Warning message:
In mean.default(forT[4], na.rm = T) :
argument is not numeric or logical: returning NA
|
Для того, чтобы функция mean() дала результат необходимо использовать другой способ доступа к данным переменной - использовать не индекс а знак доллара: forT$health. Используя индекс в одинарных квадратных скобках мы возвращаем новый фрейм данных с одной переменной, используя же знак доллара мы возвращаем вектор значений. Это связано с тем, что фреймы данных являются частным случаем списков, для которых работают различные способы доступа к данным. Об этом рассказано в одной из последующих глав.
В R существуют и более гибкие методы (например, когда надо получить средние значения в подгруппах), о которых рассказано далее.
Расширение reshape
Суть его использования заключается в том, чтобы создать «расплавленную» версию массива данных с помощью функции melt() и далее переструктурировать ее с помощью функции cast().
В результате использования функции melt() каждая переменная размещается в своей собственной строке в соответствии с той переменной, которая обозначена в качестве группирующей (группирующих переменных может быть две и более; в этом случае можно использовать, например, следующий синтаксис - "id = c(1, 2)"):
Расширение reshape
Суть его использования заключается в том, чтобы создать «расплавленную» версию массива данных с помощью функции melt() и далее переструктурировать ее с помощью функции cast().
В результате использования функции melt() каждая переменная размещается в своей собственной строке в соответствии с той переменной, которая обозначена в качестве группирующей (группирующих переменных может быть две и более; в этом случае можно использовать, например, следующий синтаксис - "id = c(1, 2)"):
15 16 17 18 | > install.packages("reshape") # устанавливаем расширение
> library(reshape) # запускаем расширение
> x <- forT[3:5] # создаем массив для работы
> meltDF <- melt(x, id = 1) # "расплавляем" массив с группирующей переменной freedom
|
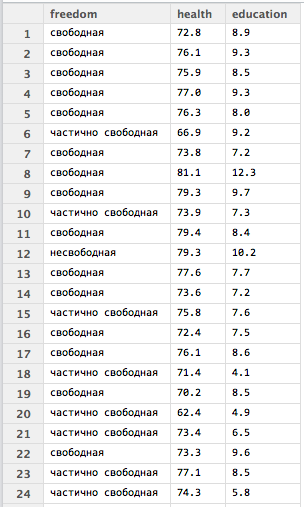
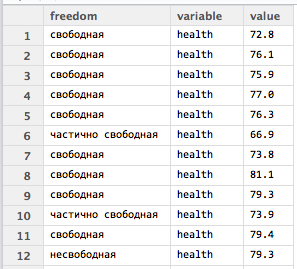
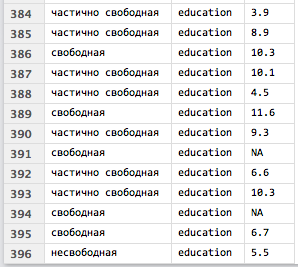
Теперь используя расплавленный массив можно перейти к обобщению данных.
Функция cast() принимает в качестве аргументов:
Если переменных более двух, то формула будет иметь следующий вид: переменная 1 в строке + переменная 2 в строке + ... ~ переменная 1 в столбце + переменная 2 в столбце + ...
Функция cast() принимает в качестве аргументов:
- "расплавленный" массив данных;
- формула, которая задает строки и столбцы переструткурированных данных;
- обобщающая функция (в случае необходимости).
Если переменных более двух, то формула будет иметь следующий вид: переменная 1 в строке + переменная 2 в строке + ... ~ переменная 1 в столбце + переменная 2 в столбце + ...
19 20 21 22 23 24 | > cast(meltDF, freedom ~ variable, mean, na.rm = T)
freedom health education
1 свободная 75.31609 9.430864
2 частично свободная 66.21356 6.252542
3 несвободная 65.25000 6.479545
4 NA 56.00000 4.200000
|
Как видно, формула построена таким образом, что в строках размещается группирующая переменная (точнее ее категории), а в столбцах - "расплавленная" часть массива, состоящая из остальных переменных.
В качестве обобщающей функции можно использовать и другие статистики - стандартное отклонение, сумму, минимум, максимум и т.д..
Расширение reshape также позволяет переструктурировать исходный набор данных без использования третьего аргумента, т.е. функций. В данном случае осуществляется изменение расположения данных исходного массива (меняются характеристики строк и столбцов), без появления аггрегированных показателей. Вместе с тем, такого рода преобразования приемлемы для случаев с небольшим количеством наблюдений.
Функция aggregate()
Действие этой функции схоже с применением расширения reshape, с тем исключением, что функция aggregate() только обобщает данные и не может их переструктурировать.
В качестве аргументов функция принимает:
В качестве обобщающей функции можно использовать и другие статистики - стандартное отклонение, сумму, минимум, максимум и т.д..
Расширение reshape также позволяет переструктурировать исходный набор данных без использования третьего аргумента, т.е. функций. В данном случае осуществляется изменение расположения данных исходного массива (меняются характеристики строк и столбцов), без появления аггрегированных показателей. Вместе с тем, такого рода преобразования приемлемы для случаев с небольшим количеством наблюдений.
Функция aggregate()
Действие этой функции схоже с применением расширения reshape, с тем исключением, что функция aggregate() только обобщает данные и не может их переструктурировать.
В качестве аргументов функция принимает:
- часть фрейма, по которой необходимо получить сводку;
- одна или несколько группирующих переменных;
- функция, которая будет использоваться для обобщения.
25 26 27 28 29 30 31 32 | > aggregate(x[4:6], x["region"], mean, na.rm = T)
region health education income
1 Южная и северная Америка 74.42286 8.334286 11121.029
2 Западная Европа 80.54400 10.426087 30285.261
3 Средний восток и Северная Африка 74.12778 7.066667 19584.778
4 Центральная и южная Африка (на юг от Сахары) 56.64375 4.544681 3385.191
5 Центральная и восточная Европа/Евразия 72.82222 10.725926 11255.778
6 Азиатско-Тихоокеанский регион 71.97000 7.434286 11025.114
|
Если необходимо указать несколько группирующих переменных, то следует использовать вектор имен. Например: x[c("region", "freedom")].
статью подготовил кандидат социологических наук Сергей Дембицкий
Вверх
blog comments powered by Disqus