Среда статистических вычислений R: краткая история возникновения, преимущества и недостатки, текущее состояние использования

Прежде чем перейти к рассмотрению заявленных в названии статьи вопросов, хочется сказать о следующем. Отечественная социология демонстрирует удивительную инертность во многих вещах. Но если ситуацию с освоением качественного подхода можно объяснить историческими особенностями нашей социологии, то недостаток, а часто и отсутствие, внимания к современным разработкам в области количественного социологии не всегда легко понять. Исходя из этого, главная задача данной статьи - познакомить читателей с чрезвычайно продуктивной и популярной зарубежом средой статистической обработки, которая уже в обозримом будущем может составить конкуренцию таким известным в нашей социологии программам обработки данных как SPSS и ОСА.
R является языком программирования (а также средой для статистических вычислений и построения графиков) [What is R?], который был разработан в 1996 году новозеландскими учеными Россом Ихака и Робертом Джентелменом при университете Окленда [R (programming language)]. R является GNU проектом, то есть свободным программным обеспечением, философия использования которого сводится к следующим принципам, а точнее свободам:
- свобода запускать программы в любых целях (свобода 0);
- свобода изучать, как работает программа, и адаптировать ее под свои нужды (свобода 1);
- свобода улучшать программу и делать ваши улучшения общедоступными к выгоде всего сообщества (свобода 3) [Операционная система GNU].
В исторической перспективе R представляет альтернативную реализацию языка программирования S. Последний был разработан в компании Bell Labs Джоном Чемберсом и его коллегами в 1976 году. В данный момент R продолжает улучшаться усилиями «R Development Core Team», членом которой также является и Д.Чемберс [R (programming language)].
R как среда статистических вычислений и построения графиков предоставляет: 1) возможность обработки и хранения данных; 2) набор операторов для обработки массивов, в том числе и матриц; 3) большую интегрированную коллекцию инструментов для анализа данных, а также графического представления результатов статистического анализа с возможностью их экспорта на жесткий диск; 4) детально проработанный, простой и эффективный язык программирования, включающий, среди прочего, условные операторы, циклы, рекурсивные функции, а также разнообразные средства для ввода и вывода данных [What is R?].
Надо подчеркнуть, что R, в отличии от таких программ как SPSS, не является оконно-кнопочной системой или системой с графическим интерфейсом пользователя (сокращенно - ГИП). Вместо ГИП в R используется интерфейс командной строки, суть которого заключается в том, что пользователь вводит все команды с клавиатуры, а система на них отвечает. Такая особенность является определяющей как в смысле ряда ключевых достоинств, так и определенных недостатков R.
Вот, что говорится об этой особенности в одной из последних русскоязычных книг по R: «...пользователь лишен возможности выбрать тип обработки из списка (меню), вместо этого он должен помнить, какие типы обработки доступны. Кроме того, ввод команд схож (а иногда и неотличим) от «настоящего» программирования, так что для работы с подобными системами нужны некоторые навыки программиста... Зато пользователь получает полный контроль над системой: он может комбинировать любые типы анализа, записывать процедуры в скрипты, (...) модифицировать вывод графиков, (...) писать расширения для системы...» [Шипунов в соавт., 2012: с. 24].
Таким образом, порог вхождения в программу может показаться пользователям, не сталкивающимся ранее с программированием, достаточно высоким. С другой стороны, команды, предназначенные для вызова базовых методов описательной статистики и статистических выводов, достаточно просты, а соответствующие результаты лаконичны. Рассмотрим пример использование линейной регрессии . Строка с соответствующим кодом будет выглядеть следующим образом:
1 2 | lm1 <- lm(eruptions ~ waiting,data=trainFaith) summary(lm1) |
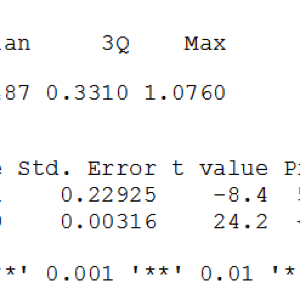
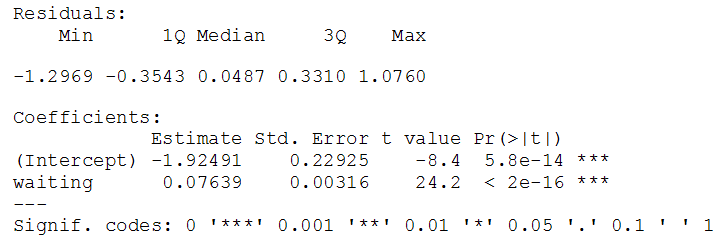
Конечно же есть и другие интересные особенности R, которые помогут принять решение относительно актуальности его изучения, а также использования :
1) Как можно было догадаться из сказанного ранее, R - абсолютно бесплатен! В то же время большинство коммерческих статистических программных платформ стоят тысячи или даже десятки тысяч долларов. Если вы владелец небольшой фирмы, научный сотрудник, преподаватель или студент, преимущество очевидно.
2) R является комплексной средой обработки данных, обеспечивающей широчайшие возможности анализа. Вам практически не придеться беспокоиться о том, что необходимый вам метод обработки данных не реализован в R.
3) В R заложенны огромные возможности визуализации данных, позволяющие создавать (и экспортировать в виде отдельных графических файлов) именно такие диаграммы, которые вам необходимы в каждом конкретном случае.
4) Изначально R разрабатывался как инструмент интерактивного изучения и анализа данных. Поэтому на каждом этапе результаты анализа могут быть зафиксированны, сохранены, модифицированны или использованы в качестве основы для других аналитических процедур.
5) R обеспечивает импорт и экспорт данных самых различных форматов, включая текстовые файлы, системы управления базами данных, статистические пакеты и специализированные хранилища данных.
6) R является, по сути, уникальной средой в смысле создания новых статистических процедур в настолько простом виде, насколько это возможно на данном этапе. Такая особенности обеспечивает высокий потенциал расширения возможностей и включения самых новых методик анализа данных.
7) Следствием предыдущей особенности является то, что передовые статистические процедуры, отсутствующие в других пакетах, становятся доступны для пользователей R в масштабах одной недели.
8) Если вы не хотите изучать основы программирования и работы с командной строкой, пользователям R доступны различные варианты ГИП.
9) R работает во всех основных операционных системах, включая Windows, Unix и Mac OS X.
Если говорить о функциональных возможностях более предметно, то согласно ориентировочным данным [Comparison of statistical packages], R входит в: б) 15% пакетов, поддерживающих все методы дисперсионного анализа; в) 10% пакетов, обеспечивающих возможность использования всех методов регрессии; г) 17% пакетов, позволяющих применять все методы анализа серий; д) 41% пакетов, предоставляющих широкий доступ к другим статистическим методам и операциям (модификация данных, описательная статистика, непараметрические тесты и многое другое).
Все эти возможности связаны, прежде всего, с большим и продуктивным сообществом, образовавшимся вокруг использования R. Об этом и других особенностях современного использования R, в сравнении с другими статистическими пакетами, пойдет речь далее.
Можно сколько угодно размышлять о плюсах и минусах статистического пакета, но итоговая оценка актуальности того или иного программного обеспечения будет, конечно же, определять тем, какое количество индивидуальных и институциональных пользователей применяют его в своей повседневной практике. Поэтому хотелось бы подробнее остановиться на этом вопросе. Источником соответствующей информации является отличная статья Роберта Муэнкена [Muenchen], посвященная популярности программного обеспечения для анализа данных. Эта работа содержит большое количество диаграмм, позволяющих лучше представить ситуацию с использованием различных аналитических платформ. Ниже я кратко остановлюсь на таких показателях, описанных в статье Муэнкена, как интернет обсуждения по электронной почте, специализированные блоги, использование в конкурсах, результаты опросов, книги, влияние на научную деятельность и рынок труда.
Интернет обсуждения по электронной почте. Наиболее интенсивно ведутся обсуждения R. Stata, SAS и SPSS занимают со второго по четвертое место соответственно. До 2006 года по этому показателю лидировал SAS, после чего он уступил первенство R, а потом стал уступать и Stata. SPSS демонстрирует сравнительно низкий уровень обсуждений во все года, предположительно, потому что является значительно более простым инструментом анализа (ГИП вместо командной строки, меньшая вариативность аналитических процедур), а также по причине наличия детальной документации.
Специализированные блоги. Блоги, как проявление добровольной активности, являются показателем неформального лидерства. В марте 2012 абсолютным лидером по этому показателю был R (365 блогов), далее шли SAS (40 блогов) и Stata (8 блогов).
Использование в конкурсах. Kaggle.com является сайтом, который спонсирует конкурсы по анализу данных. Люди и организации могут публиковать на нем данные и связанные с ними проблемы, а также обозначают вознаграждение для того, кто решит их наилучшим образом. В свою очередь аналитики создают команды, участвующие в таких конкурсах и использующие для этого то или иное программное обеспечение. На данный момент на сайте числится семдесят пять конкурсов, двенадцать из которых имеют активный статус. В пяти конкурсах в качестве вознаграждения числится опыт, в трех - работа, в двух - слава, в остальных - деньги (от 150 до 3.000.000 долларов). При этом следует понимать, что количество команд значительно превышает количество конкурсов. Так, например, за приз в три миллиона долларов в этом году соревновалось 1660 команд.
Результаты опросов. Результаты трех опросов, приведенные в статье, дают несколько противоречивые результаты относительно приоритетности использования программного обеспечения для анализа данных. Их объединяет одно - на первом месте стоит R. Позиции остальных пакетов, предположительно, зависят от состава выборки, а точнее от того, какая ее часть может позволить себе дорогие коммерческие программы.
Книги. Количество книг, написанных по тому или иному программному обеспечению, является одним из показателей его популярности. Amazon.com предоставляет хорошую возможность для оценки количества книг по определенной тематике. В нашем случае исключение составляет R, так как одна буква из алфавита не предоставляет достаточных возможностей для эффективного поиска (в этих целях Муэнкен использовал список книг с официального сайта R [Books related to R]).
Несомненным лидером здесь является SAS (почти 500 книг), далее следуют SPSS (около 150 книг), R (чуть более 100 книг) и Stata (около 50 книг).
Влияние на научную деятельность. Здесь речь идет об интенсивности использования различных программных продуктов в научных кругах. Соответствующие данные были собраны автором сайта librestats.com (по каким-то причинам он не назвал себя) на основании информации Google Scholar [Statistical Software Popularity on Google Scholar]. Два главных лидера здесь - SPSS и SAS. В середине 2000-х лидерство SPSS было подавляющим. В последние годы, позиции SPSS и SAS ухудшились, в то время как другие пакеты (JMP, Minitab, Stata, Systat, R) демонстрируют умеренный стабильный рост.
Рынок труда. Важность этого фактора очевидна. Для анализа актуальности различных программных продуктов в сфере трудоустройства Муэнкен использовал сайт Indeed.com, который, судя по всему, хорошо работает исключительно в отношении рынка труда США. С большим отрывом здесь лидирует SAS (более 12 тысяч вакансий), далее идут SPSS (чуть менее 3 тысяч вакансий), Minitab (около 1,5 вакансий), R и Stata (в обоих случаях, чуть менее 1 тысячи вакансий).
С функциональной точки зрения R представляет собой сравнительно сложный программный продукт, который, тем не менее, предоставляет широчайший спекрт возможностей в сфере анализа данных.
Если же говорить про различные сферы социального взаимодействия, где актуален анализа данных, то уже сейчас R является неформальным лидером, объединив вокруг себя большое количество людей на основании добровольной активности. С другой стороны, в коммерческой и научной сферах позиции R не так впечатляющи. Здесь он уступает SPSS и SAS. Вместе с тем, есть достаточные основания считать, что в дальнейшем позиция R в этих сферах будет улучшаться.
- default_titleWhat is R [Electronic resource]? - Accsess mode: http://www.r-project.org/about.html
- default_titleR (programming language) [Electronic resource]. - Accsess mode:
http://en.wikipedia.org/wiki/CRAN_(R_programming_language)#CRAN - default_titleОперационная система GNU [Электронный ресурс]. - Режим доступа: http://www.gnu.org/
- default_titleШипунов А.Б., Балдин Е.М., Волкова П.А., Коробейников А.И., Назарова С.А., Петров С.В., Суфиянов В.Г.
Наглядная статистика. Используем R! - М.: ДМК Пресс, 2012. - 298 с. - default_titleLeek J. Data Analysis [Electronic resource]. - Accsess mode:
https://www.coursera.org/courselivepage.apple.com/dataanalysis - default_titleKabacoff R. R in Action. - Shelter Island: Manning Publications, 2011. - 447 p.
- default_titleComparison of statistical packages [Electronic resource]. - Accsess mode:
http://en.wikipedia.org/wiki/Comparison_of_statistical_packages - default_titleMuenchen R. The Popularity of Data Analysis Software [Electronic resource]. - Accsess mode:
http://r4stats.com/articles/popularity/ - default_titleBooks related to R [Electronic resource]. - Accsess mode: http://www.r-project.org/doc/bib/R-books.html
- default_titleStatistical Software Popularity on Google Scholar [Electronic resource]. - Accsess mode:
http://librestats.com/2012/04/12/statistical-software-popularity-on-google-scholar/ - Show More
статью подготовил кандидат социологических наук Сергей Дембицкий