Время, деньги и R
Недавно при планировании онлайн опроса передо мной встал вопрос о времени его проведения. Связано это было с тем, что если я вкладываюсь в 5 минут - это одни деньги, если нет - другие. И поскольку до этого было проведено два таких опроса (Фактум Групп) и еще один опрос был проведен совместно с факультетом методологи и методов социологических исследований КНУ, то была возможность оценить скорость заполнения небольших онлайн анкет на социально-психологическую тематику. Собственно, о результатах этой оценки и пойдет речь. А еще немного про R… куда без него!

Опросы Фактум Групп.
Один опрос я заказывал в Киеве, второй - во Львове. Оба очень маленькие - по 13 вопросов. 4 демографических и 9 в виде блока индикаторов экспресс-теста. Время начала и окончания опроса для каждого респондента фиксировалось в формате «2000.01.01 00:00:00». А поскольку анализировал я это дело в R, постольку формат надо было привести к «2000-01-01 00:00:00», к которому можно применить функцию as.POSIXlt, с помощью которой можно подсчитать точную длительность времени интервью. Пример кода следующий (код приводится для Киева, для Львова - аналогичный):
distresKiev$Start <- as.character(distresKiev$date_start)
substr(distresKiev$Start,5,5) <- "-"
substr(distresKiev$Start,8,8) <- "-"
distresKiev$End <- as.character(distresKiev$date_end)
substr(distresKiev$End,5,5) <- "-"
substr(distresKiev$End,8,8) <- "-"
distresKiev$timeDif <- as.numeric(as.POSIXlt(distresKiev$End) - as.POSIXlt(distresKiev$Start))
В итоге в переменной timeDif была зафиксирована длительность интервью в секундах, что позволяет получить необходимую информацию (первая строка - Киев, вторая - Львов):
summary(distresKiev$timeDif / 60) <= делю на 60, чтобы итоги были в минутах
Min. 1stQu. Median Mean 3rdQu. Max.
0.433 1.429 1.775 2.120 2.354 10.100
0.400 1.383 1.800 2.052 2.317 11.830
Получается около 2-х минут. Можно еще посмотреть какое количество людей прошло быстрее чем за две и три минуты:
sum(distresKiev$timeDif < 120) / 200 <= делю на 200 по количеству опрошенных
sum(distresKiev$timeDif < 180) / 200
В результате - около 60% и 90%. Для полноты картины графики (Киев, потом Львов):
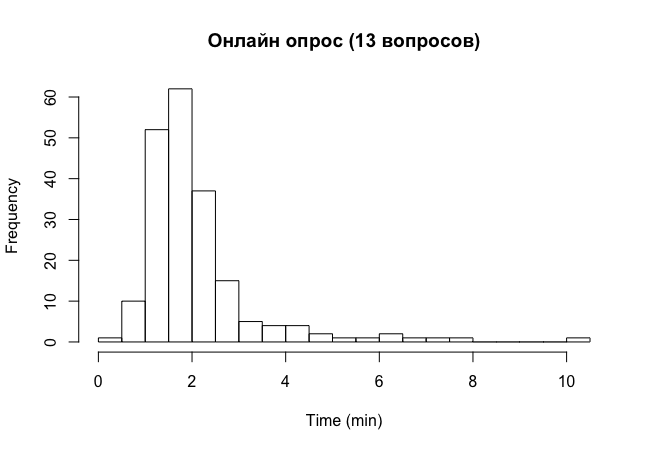
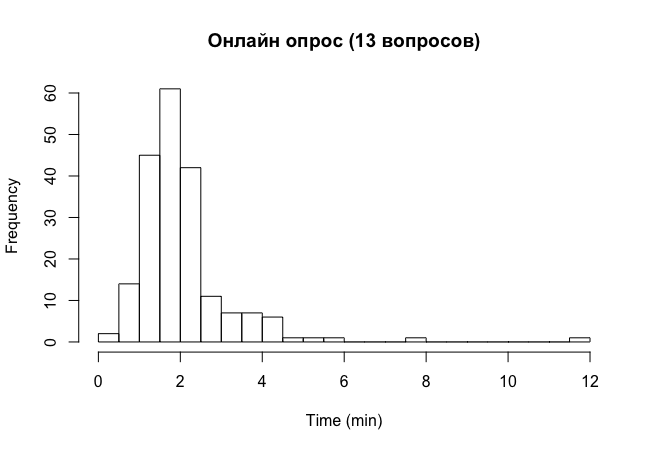
Опрос в соц сетях (я и Сидоров).
Опрос был несколько больше - на 34 вопроса. Два блока - тот же самый экспресс-тест на 9 пунктов + шкала лжи на 15. Остальное - всякий соц-дем. Со временам здесь все было гораздо проще. Если я не ошибаюсь, то время фиксировалось в формате Unix, т.е. в количестве секунд прошедших с 1 января 1970 года. Поэтому надо было просто отнять от значения для завершения интервью значения для его начала. Думаю пример кода приводить не надо. Еще одно отличие было в том, что надо было отбросить респондентов, которые не прошли тестовые методики. Также были анкеты которые заполнялись как-то подозрительно долго. Одна, например, более 20 часов. Поэтому я ограничил и время 15 минутами:
socNet <- distresOnline$timeDif[distresOnline$timeDif < 900 & !is.na(distresOnline$scl9nr) & !is.na(distresOnline$lie)]
Результаты следующие:
summary(socNet / 60)
Min. 1stQu. Median Mean 3rdQu. Max.
1.567 2.933 3.667 4.113 4.783 13.520
Здесь выходит около 4 минут. Быстрее чем за 4 минуты заполнили анкеты около 60%, чем за 5 - около 80%. График:
Опрос был несколько больше - на 34 вопроса. Два блока - тот же самый экспресс-тест на 9 пунктов + шкала лжи на 15. Остальное - всякий соц-дем. Со временам здесь все было гораздо проще. Если я не ошибаюсь, то время фиксировалось в формате Unix, т.е. в количестве секунд прошедших с 1 января 1970 года. Поэтому надо было просто отнять от значения для завершения интервью значения для его начала. Думаю пример кода приводить не надо. Еще одно отличие было в том, что надо было отбросить респондентов, которые не прошли тестовые методики. Также были анкеты которые заполнялись как-то подозрительно долго. Одна, например, более 20 часов. Поэтому я ограничил и время 15 минутами:
socNet <- distresOnline$timeDif[distresOnline$timeDif < 900 & !is.na(distresOnline$scl9nr) & !is.na(distresOnline$lie)]
Результаты следующие:
summary(socNet / 60)
Min. 1stQu. Median Mean 3rdQu. Max.
1.567 2.933 3.667 4.113 4.783 13.520
Здесь выходит около 4 минут. Быстрее чем за 4 минуты заполнили анкеты около 60%, чем за 5 - около 80%. График:
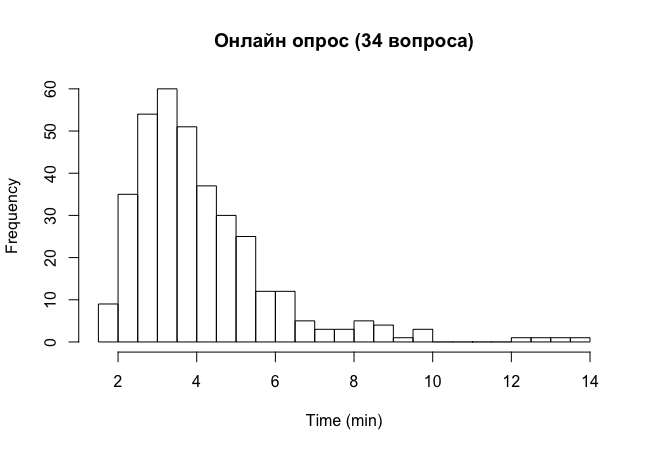
blog comments powered by Disqus