Управление данными: работа с переменными
10/11/13 14:44 Относится к категории: Анализ данных | R

Довольно часто подготовка к анализу может занимать намного больше времени, чем сам анализ. Поэтому проблемы управления данными занимают важное место в аналитическом процессе. И поскольку R является не только средой статистической обработки данных, но и языком программирования, он предоставляет множество инструментов по управлению данными.
В сегодняшней статье я хочу коснуться только части из них, а именно: вычисления новых переменных, перекодировки имеющихся, работы с пропущенными значениями, "склеивания" массивов, выборки переменных и наблюдений.
Вычисление новых переменных
В самом простом виде, для вычисления новых переменных используются простые математические операции:
а) сложение: +
б) вычитание: -
в) умножение: *
г) деление: /
д) возведение в степень: ^ или **
е) модуль: x%%y; пример: 7%%4 = 3 (т.е. находится остаток от деления)
ж) целочисленное деление: x%/%y; пример: 7%/%4 = 1
Для вычисления можно использовать различные варианты синтаксиса (здесь я продолжу использовать данные, созданные в предыдущей статье). Найдем, каков доход респондентов гривневом эквиваленте (изначально он был указан в долларах). Первый вариант перекодировки осуществлен с помощью использования непосредственных математических операций (см.строку 1 синтаксиса).
Второй вариант заключается в использовании функции transform(). В качестве примера я рассчитаю ту же переменную, что и в предыдущем случае (она просто перезапишется поверх уже созданной), а также переменную о количестве долларов, зарабатываемых респондентом за день из расчета 20 рабочих дней в месяце (см.строку 5 синтаксиса).
В самом простом виде, для вычисления новых переменных используются простые математические операции:
а) сложение: +
б) вычитание: -
в) умножение: *
г) деление: /
д) возведение в степень: ^ или **
е) модуль: x%%y; пример: 7%%4 = 3 (т.е. находится остаток от деления)
ж) целочисленное деление: x%/%y; пример: 7%/%4 = 1
Для вычисления можно использовать различные варианты синтаксиса (здесь я продолжу использовать данные, созданные в предыдущей статье). Найдем, каков доход респондентов гривневом эквиваленте (изначально он был указан в долларах). Первый вариант перекодировки осуществлен с помощью использования непосредственных математических операций (см.строку 1 синтаксиса).
Второй вариант заключается в использовании функции transform(). В качестве примера я рассчитаю ту же переменную, что и в предыдущем случае (она просто перезапишется поверх уже созданной), а также переменную о количестве долларов, зарабатываемых респондентом за день из расчета 20 рабочих дней в месяце (см.строку 5 синтаксиса).
Перекодировка имеющихся переменных
При перекодировке переменных использоваться логические операторы:
а) меньше чем: <
б) меньше чем или равно: <=
в) больше чем: >
г) больше чем или равно: >=
д) равно: ==
е) не равно: !=
ж) или: | (вертикальный слеш, а не буква)
з) и: &
В процессе присваивания новых значений логические условия задаются в квадратных скобках. Каждая новая категория может задаваться отдельным выражением (см.строки 15-17 синтаксиса). Для примера я разделю всех респондентов на две группы - на тех, кто зарабатывает менее 500 долларов, и на всех остальных.
То же самое, но в рамках одного выражения можно сделать используя функцию within() [смотри строку 21 и далее синтаксиса]. Обратите внимание, что при использовании функции within(), каждая команда в фигурных скобках не отделяется от следующей запятой и начинается с новой строки. Такой способ является достаточно удобным, т.к. такой синтаксис значительно легче прочитать и понять. Такой способ работает именно для функций с использованием фигурных скобок.
При перекодировке переменных использоваться логические операторы:
а) меньше чем: <
б) меньше чем или равно: <=
в) больше чем: >
г) больше чем или равно: >=
д) равно: ==
е) не равно: !=
ж) или: | (вертикальный слеш, а не буква)
з) и: &
В процессе присваивания новых значений логические условия задаются в квадратных скобках. Каждая новая категория может задаваться отдельным выражением (см.строки 15-17 синтаксиса). Для примера я разделю всех респондентов на две группы - на тех, кто зарабатывает менее 500 долларов, и на всех остальных.
То же самое, но в рамках одного выражения можно сделать используя функцию within() [смотри строку 21 и далее синтаксиса]. Обратите внимание, что при использовании функции within(), каждая команда в фигурных скобках не отделяется от следующей запятой и начинается с новой строки. Такой способ является достаточно удобным, т.к. такой синтаксис значительно легче прочитать и понять. Такой способ работает именно для функций с использованием фигурных скобок.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | > someData$grivni <- someData$income * 8.15 # создаем новую переменную "grivni" на основании переменной "income" в массиве "someData"
> summary(someData$grivni) # выводим основные описательные статистики по новой переменной
Min. 1st Qu. Median Mean 3rd Qu. Max.
2038 2751 3464 3892 5399 6520
> someData <- transform(someData, grivni = income * 8.15, perDay = income / 20)
> # пояснения по предыдущей строке:
> # а) до знака присваивания мы указываем массив в который записываем новые переменные
> # б) в качестве первого аргумента функции мы указываем имя массива, переменные которого мы используем для вычисления
> # в) в качестве второго аргумента мы указываем имя новой переменной и после знака равно способ ее вычисления
> # г) для третьего аргумента мы повторяем действия по вычислению еще одной переменной
> # д) через запятую мы бы могли создать другие переменные, но остановимся на двух
> summary(someData$perDay)
Min. 1st Qu. Median Mean 3rd Qu. Max.
12.50 16.88 21.25 23.88 33.12 40.00
> someData$incomNew[someData$income < 500] <- 1 # записываем в новую переменную данные о тех, кто зарабатывает менее 500$
> someData$incomNew[someData$income >= 500] <- 2 # записываем в новую переменную данные о тех, кто зарабатывает 500$ и больше
> someData$incomNew <- factor(someData$incomNew,levels = c(1,2),ordered=T,labels=c("менее 500$","более 500$")) # создаем упорядоченный фактор
> summary(someData$incomNew)
менее 500$ более 500$
7 5
> someData <- within(someData,{ # указываем массив данных, в котором находятся переменные
incomNew <- NA # создаем новую переменную, состоящую из пропущенных значений
incomNew[income < 500] <- 1 # записываем в новую переменную данные о тех, кто зарабатывает менее 500$
incomNew[income >= 500] <- 2 #записываем в новую переменную данные о тех, кто зарабатывает 500$ и больше
})
> someData$incomNew <- factor(someData$incomNew,levels = c(1,2),ordered=T,labels=c("менее 500$","более 500$")) # создаем упорядоченный фактор
> summary(someData$incomNew)
менее 500$ более 500$
7 5
|
Работа с пропущенными значениями
В процессе подготовки массива данных к последующему анализу, пропущенные значения (NA) играют важную роль. В идеале исследователь должен обнаружить все значения в массиве, не являющиеся корректными, и заменить их пропусками. Такие некоректные значения могут оказаться в данных в таких случаях: а) если была предоставлена очевидно неправдивая информация (например, 15-летний респондент, ответивший на вопрос о том, как он голосовал на выборах); б) совершены ошибки при заполненении анкеты (например, в вопросе, предполагающем выбор только одного варианта ответа, отмечено несколько); в) ошибки ввода данных.
Для перекодировки значений в пропущенные следует использовать следующее общее выражение: dataFrameName$variableName[логическое условие] <- NA. То есть применяется тот же синтаксис, что и при перекодировке переменных. Для примера я добавлю в массив два наблюдения (строки синтаксиса 30 и 31), в которых заявленная заработная плата будет очевидно неверной (5$ и 5000000$). Далее я заменю их на пропущенные значения (смотри строку синтаксиса 31). Конечно же, я могу заменить эти значения на пропуски и вручную с помощью функции fix(). Но если наблюдений в массиве будет несколько тысяч, то непосредственная, а не программная, проверка теряет всякий смысл.
В процессе подготовки массива данных к последующему анализу, пропущенные значения (NA) играют важную роль. В идеале исследователь должен обнаружить все значения в массиве, не являющиеся корректными, и заменить их пропусками. Такие некоректные значения могут оказаться в данных в таких случаях: а) если была предоставлена очевидно неправдивая информация (например, 15-летний респондент, ответивший на вопрос о том, как он голосовал на выборах); б) совершены ошибки при заполненении анкеты (например, в вопросе, предполагающем выбор только одного варианта ответа, отмечено несколько); в) ошибки ввода данных.
Для перекодировки значений в пропущенные следует использовать следующее общее выражение: dataFrameName$variableName[логическое условие] <- NA. То есть применяется тот же синтаксис, что и при перекодировке переменных. Для примера я добавлю в массив два наблюдения (строки синтаксиса 30 и 31), в которых заявленная заработная плата будет очевидно неверной (5$ и 5000000$). Далее я заменю их на пропущенные значения (смотри строку синтаксиса 31). Конечно же, я могу заменить эти значения на пропуски и вручную с помощью функции fix(). Но если наблюдений в массиве будет несколько тысяч, то непосредственная, а не программная, проверка теряет всякий смысл.
"Склеивание" массивов
"Склеивание" массивов имеет отношение к добавлению в массив новых переменных (т.е. столбцов) или наблюдений (т.е. строк) из других массивов.
Для добавления столбцов используется функция merge(), аргументами которой являются имена фреймов, подлежащих объединению, а также название ключевой переменной, которая задает порядок объединения и имеет следующий вид: by=«variableName». Ключевая переменная задает уникальное имя или номер наблюдения в каждом из фреймов так, чтобы после склеивания, наблюдения из нового фрейма заняли нужные строки в старом фрейме. Если объединение не предусматривает использования ключевой переменной (наблюдения в обоих массивах расположены одинаково), можно использовать функцию cbind(), в которой просто указываются имена фреймов. При этом количество строк в каждом фрейме должно быть одинаковым.
Для объединения строк используется функция rbind(), в качестве аргументов которой необходимо указать только название фреймов. При этом все они должны иметь одинаковый набор переменных, хотя их порядок в каждом из массивов не играет роли. Если какие-то фреймы имеют переменные, которых нет в других фреймах, то можно или удалить лишние (формат синтаксиса следующий: dataFrame$oldVar <- NULL) или создать недостающие переменные и присвоить им пропуски (формат синтаксиса следующий: dataFrame$newVar <- NA).
"Склеивание" массивов имеет отношение к добавлению в массив новых переменных (т.е. столбцов) или наблюдений (т.е. строк) из других массивов.
Для добавления столбцов используется функция merge(), аргументами которой являются имена фреймов, подлежащих объединению, а также название ключевой переменной, которая задает порядок объединения и имеет следующий вид: by=«variableName». Ключевая переменная задает уникальное имя или номер наблюдения в каждом из фреймов так, чтобы после склеивания, наблюдения из нового фрейма заняли нужные строки в старом фрейме. Если объединение не предусматривает использования ключевой переменной (наблюдения в обоих массивах расположены одинаково), можно использовать функцию cbind(), в которой просто указываются имена фреймов. При этом количество строк в каждом фрейме должно быть одинаковым.
Для объединения строк используется функция rbind(), в качестве аргументов которой необходимо указать только название фреймов. При этом все они должны иметь одинаковый набор переменных, хотя их порядок в каждом из массивов не играет роли. Если какие-то фреймы имеют переменные, которых нет в других фреймах, то можно или удалить лишние (формат синтаксиса следующий: dataFrame$oldVar <- NULL) или создать недостающие переменные и присвоить им пропуски (формат синтаксиса следующий: dataFrame$newVar <- NA).
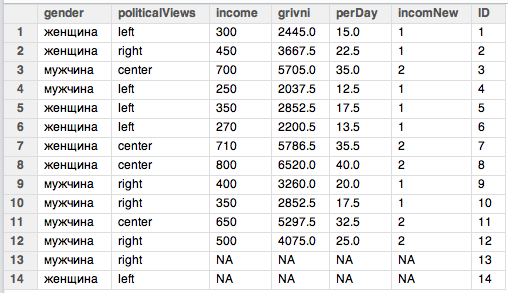
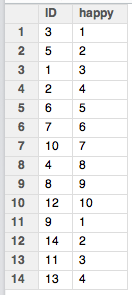
Рассмотрим примеры. Для использования функции merge() необходимо создать новую переменную, которая бы указывала номер наблюдения (смотри строку синтаксиса 33). Далее создаем новый пустой фрейм данных и вводим в него данные (смотри строки синтаксиса 34, 35). При этом одна из переменных указывает номер наблюдения (та самая "ID"), а вторая является содержательной - например, уровень счастья по 10-бальной шкале. То как теперь выглядят фреймы данных можно посмотреть ниже на рисунке 1.
Наконец, можно слить массивы (смотри строку синтаксиса 36). Если бы наблюдения в обоих фреймах были расположены одинаково, можно было бы использовать функцию cbind(). При этом надо было бы указать только имена фреймов данных. Аналогично для функции rbind().
Наконец, можно слить массивы (смотри строку синтаксиса 36). Если бы наблюдения в обоих фреймах были расположены одинаково, можно было бы использовать функцию cbind(). При этом надо было бы указать только имена фреймов данных. Аналогично для функции rbind().
30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | > someData[13,] <- data.frame(c("мужчина"),c("right"),c(5),c(NA),c(NA),c(NA)) # создаем новое наблюдение в строке 13
> someData[14,] <- data.frame(c("женщина"),c("left"),c(5000000),c(NA),c(NA),c(NA)) # создаем новое наблюдение в строке 14
> someData$income[someData$income < 25 | someData$income > 30000] <- NA # теперь для наблюдений 13 и 14 осталась информация только про пол и политические взгляды
> someData$ID <- 1:14 # создаем новую переменную с переменными от 1 до 14
> lostData <- data.frame() # создаю новый пустой фрейм
> fix(lostData) # ввожу данные в новый фрейм
> someData <- merge(someData, lostData, by = "ID") # склеиваем массивы по переменной "ID" и записываем все данные в основной фрейм данных
> someData # проверяем как выглядит массив
ID gender politicalViews income grivni perDay incomNew happy
1 1 женщина left 300 2445.0 15.0 1 3
2 2 женщина right 450 3667.5 22.5 1 4
3 3 мужчина center 700 5705.0 35.0 2 1
4 4 мужчина left 250 2037.5 12.5 1 8
5 5 женщина left 350 2852.5 17.5 1 2
6 6 женщина left 270 2200.5 13.5 1 5
7 7 женщина center 710 5786.5 35.5 2 6
8 8 женщина center 800 6520.0 40.0 2 9
9 9 мужчина right 400 3260.0 20.0 1 1
10 10 мужчина right 350 2852.5 17.5 1 7
11 11 мужчина center 650 5297.5 32.5 2 3
12 12 мужчина right 500 4075.0 25.0 2 10
13 13 мужчина right NA NA NA NA 4
14 14 женщина left NA NA NA NA 2
|
Массив данных someData
Массив данных lostData
Выборка переменных
Выборка из массива может осуществляться как в отношении переменных, так и в отношении наблюдений. В первом случае, обычно, создаются новые фреймы. Типичным синтаксисом при этом является простое присваивание, в котором для исходного массива в квадратных скобках указывается соответствующее индексирование: newData <- oldData[rowIndex, columnIndex]. При этом, если нет необходимости отбирать наблюдения, а только переменные, то на месте rowIndex ничего не ставится, но запятая ставится и уже после нее - индекс для соответствующих переменных. Индексирование в R начинается с 1. Таким образом первая переменная (первый столбец) имеет индекс 1, вторая - 2, третья - 3 и т.д. Рассмотрим несколько примеров с отбором переменных (смотри строки с 53 по 58 синтаксиса).
Следующий способ заключается в том, чтобы создать вектор из имен переменных, которые необходимо включить в новый массив и использовать его в качестве определителя в квадратных скобках (смотри строки 59 и 60 синтаксиса). Такой способ предполагает работу только с переменными, поэтому запятая не ставится.
Наконец, можно вместо включения необходимых переменных, исключить ненужные. Базовый способ при этом - использование индексов со знаком минус. В таком случае соответствующие переменные не будут включены в новый фрейм данных (смотри строку 61 синтаксиса).
Существуют и другие более сложные (и соответственно более продуктивные в определенных ситуациях) способы, но на них мы останавливаться не будем.
Выборка из массива может осуществляться как в отношении переменных, так и в отношении наблюдений. В первом случае, обычно, создаются новые фреймы. Типичным синтаксисом при этом является простое присваивание, в котором для исходного массива в квадратных скобках указывается соответствующее индексирование: newData <- oldData[rowIndex, columnIndex]. При этом, если нет необходимости отбирать наблюдения, а только переменные, то на месте rowIndex ничего не ставится, но запятая ставится и уже после нее - индекс для соответствующих переменных. Индексирование в R начинается с 1. Таким образом первая переменная (первый столбец) имеет индекс 1, вторая - 2, третья - 3 и т.д. Рассмотрим несколько примеров с отбором переменных (смотри строки с 53 по 58 синтаксиса).
Следующий способ заключается в том, чтобы создать вектор из имен переменных, которые необходимо включить в новый массив и использовать его в качестве определителя в квадратных скобках (смотри строки 59 и 60 синтаксиса). Такой способ предполагает работу только с переменными, поэтому запятая не ставится.
Наконец, можно вместо включения необходимых переменных, исключить ненужные. Базовый способ при этом - использование индексов со знаком минус. В таком случае соответствующие переменные не будут включены в новый фрейм данных (смотри строку 61 синтаксиса).
Существуют и другие более сложные (и соответственно более продуктивные в определенных ситуациях) способы, но на них мы останавливаться не будем.
Выборка наблюдений
Для отбора наблюдений (т.е. строк) существует три основных подхода. Во-первых, можно использовать присваивание с индексированием в квадратных скобках. Во-вторых, можно отобрать наблюдения в соответствии с заданными логическими условиями (в этом случае используется функция which()). В-третьих, можно извлечь случайную выборку с помощью функции sample(). Рассмотрим каждый из этих способов.
Первый подход хорош в тех случаях, когда последовательность наблюдений отражает последовательность изучения или развития определенного феномена. В таком случае очень легко отделить интересующий нас промежуток времени. В нашем же случае ситуация с наблюдениями совсем не такая. В любом случае, отберем из массива всех респондентов женского пола (см.строки 62 и 63 синтаксиса). Конечно же, такой способ отбора в данном случае явно не подходит (если бы было большое количество наблюдений, то составление вектора стало бы слишком глупым занятием). Значительно легче для решения этой задачи использовать второй подход (смотри строку 73 синтасиса). В отличии от предыдущих случаев, когда использовались логические условия, здесь необходимо указывать их в качестве параметра функции which(). Результат будет таким же, как и при использовании первого подхода.
Для отбора наблюдений (т.е. строк) существует три основных подхода. Во-первых, можно использовать присваивание с индексированием в квадратных скобках. Во-вторых, можно отобрать наблюдения в соответствии с заданными логическими условиями (в этом случае используется функция which()). В-третьих, можно извлечь случайную выборку с помощью функции sample(). Рассмотрим каждый из этих способов.
Первый подход хорош в тех случаях, когда последовательность наблюдений отражает последовательность изучения или развития определенного феномена. В таком случае очень легко отделить интересующий нас промежуток времени. В нашем же случае ситуация с наблюдениями совсем не такая. В любом случае, отберем из массива всех респондентов женского пола (см.строки 62 и 63 синтаксиса). Конечно же, такой способ отбора в данном случае явно не подходит (если бы было большое количество наблюдений, то составление вектора стало бы слишком глупым занятием). Значительно легче для решения этой задачи использовать второй подход (смотри строку 73 синтасиса). В отличии от предыдущих случаев, когда использовались логические условия, здесь необходимо указывать их в качестве параметра функции which(). Результат будет таким же, как и при использовании первого подхода.
Случайная выборка в отношении фрейма данных может применяться в тех случаях, когда он настолько огромен, что его обработка занимает слишком большое количество времени (лично я с такими огромными массивами не работал). Вместе с тем, сама функция sample() может быть полезна во множестве других случаев. Поэтому давайте ее рассмотрим. В качестве ее аргументов указываются: диапазоном из которого производится отбор, размер выборки и параметр замены (определяет может ли одно и то же наблюдение быть отобранным два и более раза). Отберем случайным образом из нашего массива 4 наблюдения (смотри строку синтаксиса 74).
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | > names(someData) # с помощью функции names() уточняем индексы переменных
[1] "ID" "gender" "politicalViews" "income" "grivni" "perDay" "incomNew"
[8] "happy"
> varSample <- someData[ , 2:4] # создаем подвыборку из трех изначальны переменных (пол, политические взгляды и доход в долларах)
> vars <- c(2,8) # создаем вектор с индексами требуемых переменных (пол и уровень счастья)
> varSample2 <- someData[ , vars] # создаем подвыборку с помощью только что созданного вектора
> varNames <- c("income","grivni","perDay","incomNew") # создаем вектор с требуемыми именами
> varSample3 <- someData[varNames] # создаем подвыборку на основании только что созданного вектора
> varSample4 <- someData[ , c(-1,-8)] # создаем новый массив, из которого исключаем 1 и 8 переменную
> forGender <- c(1,2,5,6,7,8,14) # создаем вектор с номерами респондентов женского пола
> women <- someData[forGender , ] # создаем подвыборку женщин с помощью только что созданного вектора
> women # смотрим, что получилось
ID gender politicalViews income grivni perDay incomNew happy
1 1 женщина left 300 2445.0 15.0 1 3
2 2 женщина right 450 3667.5 22.5 1 4
5 5 женщина left 350 2852.5 17.5 1 2
6 6 женщина left 270 2200.5 13.5 1 5
7 7 женщина center 710 5786.5 35.5 2 6
8 8 женщина center 800 6520.0 40.0 2 9
14 14 женщина left NA NA NA NA 2
> women <- someData[which(someData$gender == "женщина") , ] # отбираем из массива только женщин
> randomSample <- someData[sample(1:nrow(someData), 4, replace=FALSE) , ] # создаем случайную выборку из четырех наблюдений
> # пояснения по предыдущей строке:
> # а) указывая диапазон из которого необходимо осуществить отбор мы используем функцию nrow(), которая вернет значение, равное количеству строк в массиве
> # б) 4 на месте второго аргумента говорит о том, что будет отобрано ровно 4 наблюдения
> # в) выражение "replace=FALSE" говорит о том, что каждое наблюдение может быть отобрано только один раз
> randomSample # смотрим, что получилось
ID gender politicalViews income grivni perDay incomNew happy
10 10 мужчина right 350 2852.5 17.5 1 7
2 2 женщина right 450 3667.5 22.5 1 4
9 9 мужчина right 400 3260.0 20.0 1 1
5 5 женщина left 350 2852.5 17.5 1 2
> # г) конечно же функция sample() может применяться как самостоятельная, или в рамках других выражений:
> sort(sample(1:100, 10, replace=FALSE)) # извлекаем из номеров от 1 до 100 случайную выборку из 10 элементов и сортируем ее
[1] 12 28 31 43 57 61 69 76 91 96
|
статью подготовил кандидат социологических наук Сергей Дембицкий
Вверх
blog comments powered by Disqus