Уменьшение погрешностей, возникающих в результате округления выборки
22/09/15 19:07 Относится к категории: Эмпирическая социология | Выборка

Собственно мысли Антона:
Один из неочевидных источников погрешности выборки - ошибки, возникающие вследствие округления чисел при ее построении.
При проектировании выборки для эмпирического исследования обычно работают с дробными числами. Например, объем страты рассчитывается как пропорциональная доля выборки, что обычно является действительным (дробным) числом. Но на последнем этапе, при переходе к количеству респондентов, все числа необходимо округлить до натуральных (мы не можем планировать страты, например, с 12.6 респондентами). Для этого обычно применяют классическое округления до ближайшего натурального числа или до ближайшего большего натурального числа [Turner, 2003; Suhr 2009; Westfall 2011; Chaudhuri, 2003]. Вместе с тем, применение обычных правил дает неудовлетворительный результат: объем выборки может измениться - мы можем получить меньшую выборку, но с худшей репрезентативностью, или же большую выборку, что влияет на удорожание исследования. В обоих случаях может появиться такая погрешность как смещение структуры выборочной совокупности относительно генеральной. В современной литературе этой проблеме не посвящается достаточного внимания. Она не рассматривается, поскольку воспринимается как очевидная или неважна. Однако на практике встреча с ней является неизбежной и способы ее преодоления являются очевидными.
В данной работе предлагается алгоритм вычисления объема компонентов выборки (страт или квот) для случайной выборки с наименьшим отклонением от заданных параметров. Он позволяет минимизировать ухудшение соответствия структур выборки и генеральной совокупности, а также приблизить финальную репрезентативность к первоначально запланированной.
Основная сложность заключается в том, что после округления числа, у него «исчезает» или «появляется» часть, представляющая собой разницу между исходным числом и округленным числом, то есть остаток округления. Накопление таких остатков и приводит к общей разнице между суммами начального ряда значений и результирующего (т.е. округленного). Данный алгоритм позволяет учесть соответствующие расхождения, благодаря добавлению выявленной на данном этапе разницы к еще неокругленному числу на следующем. При этом для избавления от возможного систематического сдвига при округлении чисел, которые идут рядом в таблице квот, используется случайный выбор элемента, который будет округляться следующим, то есть к которому будет прибавляться остаток от предыдущего округления.
Алгоритм лучше всего представить в виде блок-схемы:
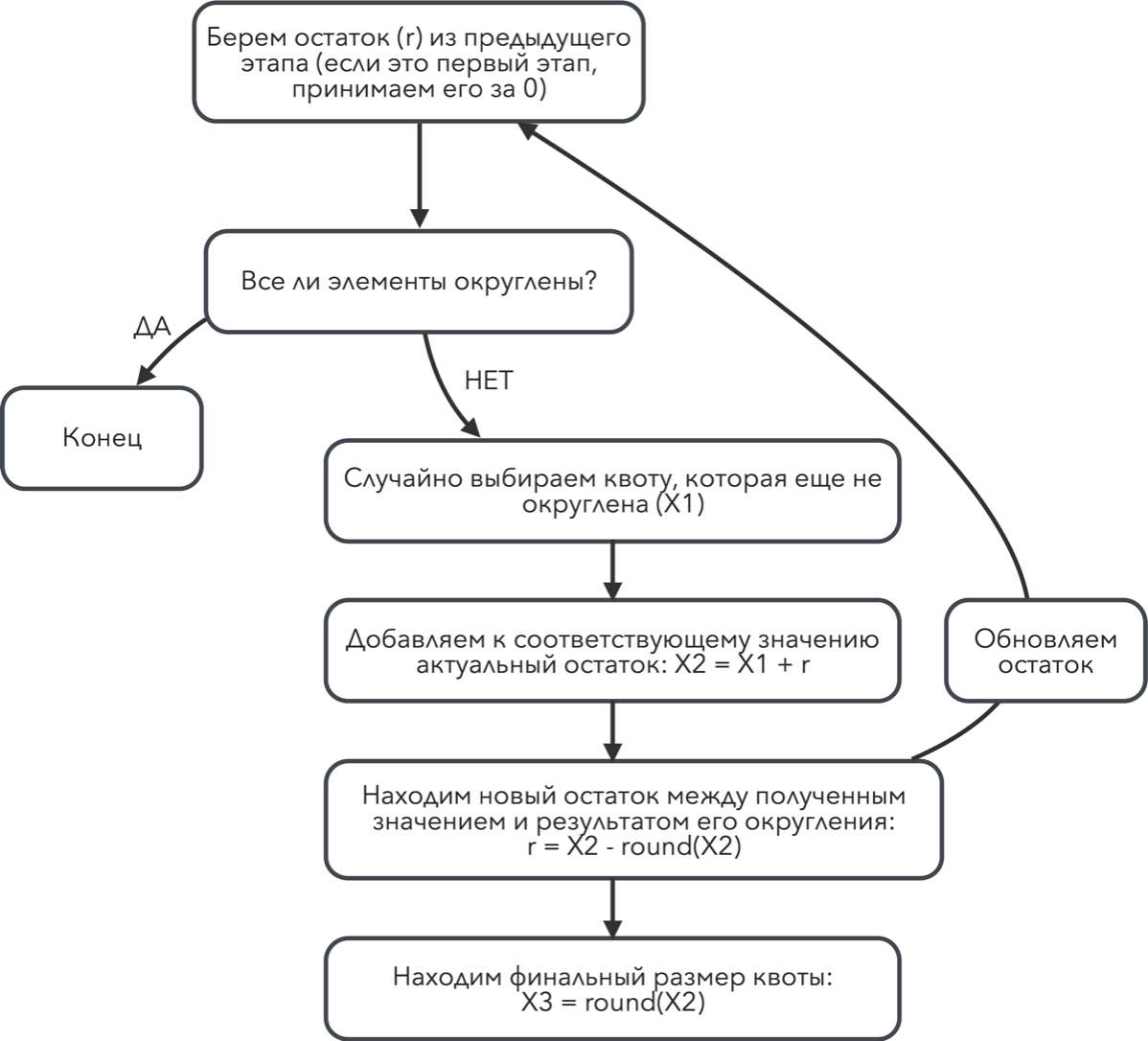
Операции добавления остатка от прошлого округления, расчета новой разницы, округление числа и случайный отбор следующего числа повторяются до тех пор пока не будут округлены все элементы.
Так как алгоритм содержит в себе случайный отбор, каждое новое его использование на одних и тех же исходных данных будет давать немного отличающийся результат.
Основная сложность заключается в том, что после округления числа, у него «исчезает» или «появляется» часть, представляющая собой разницу между исходным числом и округленным числом, то есть остаток округления. Накопление таких остатков и приводит к общей разнице между суммами начального ряда значений и результирующего (т.е. округленного). Данный алгоритм позволяет учесть соответствующие расхождения, благодаря добавлению выявленной на данном этапе разницы к еще неокругленному числу на следующем. При этом для избавления от возможного систематического сдвига при округлении чисел, которые идут рядом в таблице квот, используется случайный выбор элемента, который будет округляться следующим, то есть к которому будет прибавляться остаток от предыдущего округления.
Алгоритм лучше всего представить в виде блок-схемы:
Операции добавления остатка от прошлого округления, расчета новой разницы, округление числа и случайный отбор следующего числа повторяются до тех пор пока не будут округлены все элементы.
Так как алгоритм содержит в себе случайный отбор, каждое новое его использование на одних и тех же исходных данных будет давать немного отличающийся результат.
blog comments powered by Disqus