Создание массива данных в R
18/10/13 18:35 Относится к категории: Анализ данных | R

Это первая из серии статей, посвященных основам использования R. Одной из их особенностей будет направленность на специфику социологического анализа. Следовательно те моменты, которые есть в R, но не касаются социологии я буду намерено опускать.
Как и в других средах анализа данных, в R можно открыть, создать или импортировать данные. Я остановлюсь на каждом из этих способов. А поскольку вопрос создания массива данных тесно связан с типами и структурами данных, постольку соответствующим темам также будет уделено внимание.
Здесь и далее я буду прибегать к использованию RStudio, представляющую собой "оболочку" для работы с R. Файлы для установки можно скачать здесь. RStudio также как и R является абсолютно бесплатной.
Типы и структуры данных
Следует различать структуры данных (способ организации) и их тип (сущность отображаемой в данных информации).
R включает обычные для многих других языков программирования типы данных, из которых нам будут интересны базовые: числовой, текстовой и логический (правда/ложь).
Далее приведен синтаксис для создания трех скаляров (или просто переменных) по каждому из типов:
Следует различать структуры данных (способ организации) и их тип (сущность отображаемой в данных информации).
R включает обычные для многих других языков программирования типы данных, из которых нам будут интересны базовые: числовой, текстовой и логический (правда/ложь).
Далее приведен синтаксис для создания трех скаляров (или просто переменных) по каждому из типов:
1 2 3 | > char <- "R - это круто!" > number <- 100 > socrat <- TRUE |
После запуска этого синтаксиса в части окна Workspace (т.н. рабочая область) появится три новых объекта соответствующего типа. Хочется отметить, что результатом анализа в R часто является не только получение содержательных результатов, но и специфических объектов, в которых эти результаты записаны особым образом. Благодаря этому, открывается возможность дальнейшего использования этих объектов средствами языка R, что значительно обогащает аналитический процесс.
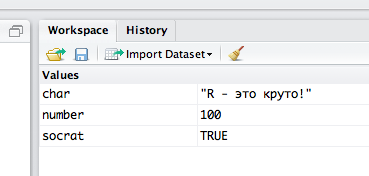
Тип каждого из объектов можно проверить с помощью функции typeof():
4 5 6 7 8 9 | > typeof(char) [1] "character" > typeof(number) [1] "double" > typeof(socrat) [1] "logical" |
Пусть вас не смущает результат проверки скаляра "number" - тип "double" является одним из способов фиксации числовых данных.
Если говорить о структурах данных, то здесь я коснусь векторов и фреймов (о скалярах уже было сказано). В дальнейших статьях я также обращусь к спискам.
Если говорить в общем, то различные структуры данных отличаются между собой тем, какие типы данных они могут содержать, как они создаются, какова их комплексность и тем, каков способ определения и доступа к их элементам. Эти особенности будут рассмотрены в последующих главах.
Вектор - это одномерный массив, который может включать данные только одного типа. Для создания вектора используется функция c():
Если говорить в общем, то различные структуры данных отличаются между собой тем, какие типы данных они могут содержать, как они создаются, какова их комплексность и тем, каков способ определения и доступа к их элементам. Эти особенности будут рассмотрены в последующих главах.
Вектор - это одномерный массив, который может включать данные только одного типа. Для создания вектора используется функция c():
10 11 12 | > filosofId <- c(1,2,3)
> name <- c("Socrat","Aristotel","Platon")
> pravLi <- c(TRUE,FALSE,FALSE)
|
После запуска этого синтаксиса в рабочей области появится три новых объкта.
В том случае, когда в данных необходимо зафиксировать пропуски, используется значение NA. Допустим у Платона был ученик, но нам неизвестно его имя, а также то, был ли он прав. Тогда создание векторов будет выглядеть следующим образом:
В том случае, когда в данных необходимо зафиксировать пропуски, используется значение NA. Допустим у Платона был ученик, но нам неизвестно его имя, а также то, был ли он прав. Тогда создание векторов будет выглядеть следующим образом:
13 14 15 | > filosofId <- c(1,2,3,4)
> name <- c("Socrat","Aristotel","Platon",NA)
> pravLi <- c(TRUE,FALSE,FALSE,NA)
|
Поскольку имена векторов остались теми же, они просто будут перезаписаны.
Векторы достаточно часто используются в анализе, но основной формат организации данных - это фреймы. Они представляют собой таблицы, в которых строки являются наблюдениями, а столбцы - переменными. При этом каждый столбец может содержать свой собственный тип данных. Фреймы данных создаются с помощью одноименной функции:
Векторы достаточно часто используются в анализе, но основной формат организации данных - это фреймы. Они представляют собой таблицы, в которых строки являются наблюдениями, а столбцы - переменными. При этом каждый столбец может содержать свой собственный тип данных. Фреймы данных создаются с помощью одноименной функции:
16 | > istoriyaFilosofii <- data.frame(filosofId, name, pravLi) |
Фрейм также появится в рабочей области и если на него нажать, то откроется соответствующая таблица:
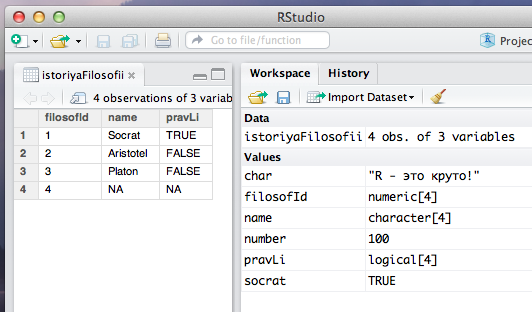
Давайте подведем итог того, как создаются объекты с помощью синтаксиса. Во-первых, мы определяем сам объект посредством его наименования (т.е. набираем имя уже созданного или еще не созданного объекта). Во-вторых, справа от этого имени мы вводим оператор присваивания, состоящий из угловой скобки (<) и знака тире (-). Наконец, справа от знака присваивания мы вводим либо значение (если создается скаляр), либо специальную функцию (например c или data.frame), в аргументах (то что располагается между скобками) которой перечисляется содержание объекта. При этом важно помнить, что все названия функция в R вводятся с помощью английской раскладки клавиатуры (не путайте "с" русское и "с" английское).
Ввод и импорт данных
Конечно же в большинстве случаев вы не будете создавать фреймы данных с помощью заранее прописанных для этого векторов (хотя такой вариант не следует исключать полностью). Значительно легче ввести данные в R с помощью функции fix() или просто загрузить уже готовый массив.
Далее приведет вариант запуска ввода данных внутри R:
Конечно же в большинстве случаев вы не будете создавать фреймы данных с помощью заранее прописанных для этого векторов (хотя такой вариант не следует исключать полностью). Значительно легче ввести данные в R с помощью функции fix() или просто загрузить уже готовый массив.
Далее приведет вариант запуска ввода данных внутри R:
17 18 | > superData <- data.frame() # создаем пустой фрейм данных > fix(superData) # запускаем окно для ввода |
После этого откроется специальное окно, в котором можно редактировать данные: вводить значения наблюдений, задавать имена переменных и менять их тип (для работы с именами надо нажать на заглавие столбца). На маке таблица имеет следующий вид (на винде будет выглядеть еще лучше):

После того, как данные введены, необходимо нажать на кнопку Quit и все изменения будут сохранены.
Если данные уже готовы и их надо просто открыть или импортировать, то для начала следует определить рабочую директорию (в которой по идее эти самые данные и размещаются). Легче всего это сделать, выбрав следующие пункты меню:
Если данные уже готовы и их надо просто открыть или импортировать, то для начала следует определить рабочую директорию (в которой по идее эти самые данные и размещаются). Легче всего это сделать, выбрав следующие пункты меню:
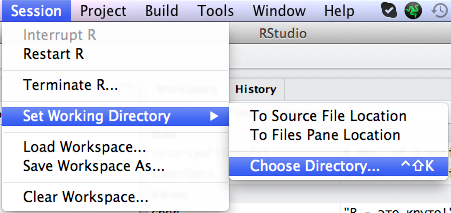
После этого надо просто выбрать соответствующую папку на вашем компьютере. В дальнейшем при открытии, импорте, экспорте и сохранении файлов R автоматически будет обращаться к ней.
При импорте данных в формате CSV (кратко о CSV-файлах) используется функцию read.table(), в которой необходимо указать ряд аргументов:
При импорте данных в формате CSV (кратко о CSV-файлах) используется функцию read.table(), в которой необходимо указать ряд аргументов:
file="file_name.csv"
header=LOGICAL (TRUE of FALSE)
sep="separator"
row.names="variable_name"
Аргумент file говорит сам за себя. Главное, чтобы файл, к которому вы обращаетесь был в рабочей директории. Аргумент header приравнивается к TRUE если первая строка в файле содержит имена переменных и к FALSE - если нет. Аргумент sep задает символ, разделяющий значения. Обычно это точка, запятая или точка с запятой. Если есть переменная, задающая наименования для каждой строки (например, имя или номер респондента), то ее название вводится в аргументе row.names.
Синтаксис может выглядеть например вот так:
Синтаксис может выглядеть например вот так:
19 | > CsvData <- read.table("nonSuperData.csv", header=TRUE, sep=",", row.names="ID")
|
В результате в рабочей области появится фрейм данных с именем CsvData.
Для импорта данных формата SPSS (а также многих других форматов) необходимо установить расширение (расширения разрабатываются самими пользователями для решения задач, выполнение которых не предусмотрено базовой версией R). Мы остановимся на расширении foreign, которое позволяет импортировать данные самых разных форматов. Установка расширений осуществляется с помощью функции install.packages():
Для импорта данных формата SPSS (а также многих других форматов) необходимо установить расширение (расширения разрабатываются самими пользователями для решения задач, выполнение которых не предусмотрено базовой версией R). Мы остановимся на расширении foreign, которое позволяет импортировать данные самых разных форматов. Установка расширений осуществляется с помощью функции install.packages():
20 21 | > install.packages("foreign")
> library(foreign)
|
После установки, перед началом работы расширение необходимо запустить с помощью функции library(). Далее можно использовать функции, предусмотренные расширением. В нашем случае это функция read.spss(), использующая следующие аргументы (не забываем про рабочую директорию):
file="file_name.sav"
use.value.labels=LOGICAL (TRUE of FALSE)
max.value.labels=Inf
to.data.frame=LOGICAL (TRUE of FALSE)
use.missings=LOGICAL (TRUE of FALSE)
Аргумент use.value.labels указывает, использовать ли имена категорий переменной, заданные в SPSS (TRUE), или только числовые значения (FALSE). max.value.labels определяет сколько категорий должна иметь переменная (если для категорий заданы имена), чтобы игнорировать их имена, а использовать только числовые значения. Значение Inf для этого аргумента задается в тех случаях, когда мы хотим использовать имена для всех категорий переменной. to.data.frame определяет, надо ли привести массив данных к формату фрейма данных, use.missings - надо ли вместо значений, зафиксированных в SPSS как пропуски, проставить NA.
Пример синтаксиса следующий:
Пример синтаксиса следующий:
22 | > SpssData <- read.spss("testData.sav", use.value.labels=TRUE, max.value.labels=Inf, to.data.frame=TRUE, use.missings=TRUE)
|
После того, как массив загружен и проведена соответствующая работа, данные можно сохранить с помощью функции save():
23 | > save("SpssData", file="finalData.RData")
|
Как вы понимаете, первый аргумент функции является названием фрейма, который необходимо сохранить, а второй - названием файла, в который данные будут записаны.
Напоследок или о чем стоит помнить
Во-первых, всегда стоит помнить о расширениях файлов или символах, которые стоят после точки в их имени. Если мы говорим о файлах с данными, то для CSV - это csv, для SPSS - sav, для R - RData.
Во-вторых, вместо сохранения фреймов данных по отдельности с помощью функции save(), можно сохранить всю рабочую область, нажав на значок дискеты. В этом случае в одном файле будут сохранены все текущие фреймы, скаляры, векторы и другие объекты, которые были созданы в процессе работы. Это удобно =)
В-третьих, открытие любых файлов R, осуществляется с помощью знакомого всем значка папки. И если вы правильно установили рабочую директорию в начале работы, то нажатие на соответствующем символе сразу же будет приводить вас к нужной папке. Альтернативный вариант - нажать вкладку "Files" в нижней правой части экрана и на файл с нужными данными.
Во-первых, всегда стоит помнить о расширениях файлов или символах, которые стоят после точки в их имени. Если мы говорим о файлах с данными, то для CSV - это csv, для SPSS - sav, для R - RData.
Во-вторых, вместо сохранения фреймов данных по отдельности с помощью функции save(), можно сохранить всю рабочую область, нажав на значок дискеты. В этом случае в одном файле будут сохранены все текущие фреймы, скаляры, векторы и другие объекты, которые были созданы в процессе работы. Это удобно =)
В-третьих, открытие любых файлов R, осуществляется с помощью знакомого всем значка папки. И если вы правильно установили рабочую директорию в начале работы, то нажатие на соответствующем символе сразу же будет приводить вас к нужной папке. Альтернативный вариант - нажать вкладку "Files" в нижней правой части экрана и на файл с нужными данными.
статью подготовил кандидат социологических наук Сергей Дембицкий
Вверх
blog comments powered by Disqus