Многие переменные (а во многих социологических исследованиях, основывающихся на массовых опросах, - подавляющее их большинство) имеют пропущенные значения. Последние ведут к снижению статистической мощности (то есть снижают вероятность нахождения реальных закономерностей в данных), а также могут быть причиной систематических ошибок [Бослаф, 2015: с. 450]. Обработка пропущенных значений является достаточно развитой исследовательской областью с общепринятой терминологией и множеством решений для различных дисциплин и конкретных исследований. С попыткой широкого обобщения основ обработки пропущенных данных в социальных науках можно ознакомиться, например, в работе Даниэля Ньюмана [Newman, 2014]. В рамках же данной статьи мы обратимся к главным понятиям этой теории, а также основным методам решения проблемы пропущенных значений. Виды пропусков Принято выделять три вида пропусков - полностью случайные, случайные и неслучайные пропуски (данная терминология ведет свое начало от известной работы Дональда Рубина [Rubin, 1976]). Полностью случайные пропуски (ПСП-допущение) имеют место в тех случаях, когда подвыборка имеющихся значений по переменной(-ым), подлежащей изучению, по-прежнему является моделью генеральной совокупности. Примером может служить случай, когда пропуски по некоторой переменной (например, политические предпочтения) не зависят от значений переменных-предикторов (например, пол, возраст, регион проживания и т.д.), а также от значений самих пропусков (например, не возникает ситуации, когда респонденты с определенной политической позицией чаще других не дают ответа на соответствующий вопрос). Выбор модели полностью случайных пропусков - единственное допущение, которое можно проверить эмпирически. Что касается случайных и неслучайных пропусков, соответствующие допущения невозможно проверить на основании имеющегося массива. При случайных пропусках (СП-допущение) их значения зависят от значений переменных-предикторов и не зависят от собственных значений пропусков. Так, если пропуски в ответах на вопрос о политических предпочтениях чаще встречаются среди людей старшего возраста (но внутри этой группы они распределены случайно), то речь идет о случайных пропусках. В этом случае возникает вероятность смещения результатов оценивания параметров по выборке в целом (если значение по соответствующей подгруппе отличается от общего среднего). Если же вероятность пропусков по определенным переменным зависит от величины самих пропущенных значений по этим переменным, то говорят о неслучайных пропусках (НП-допущение). Например, люди с левыми политическими взглядами с меньшей вероятностью склонны сообщать соответствующую информацию. Такие пропуски вносят систематические ошибки в результаты анализа.
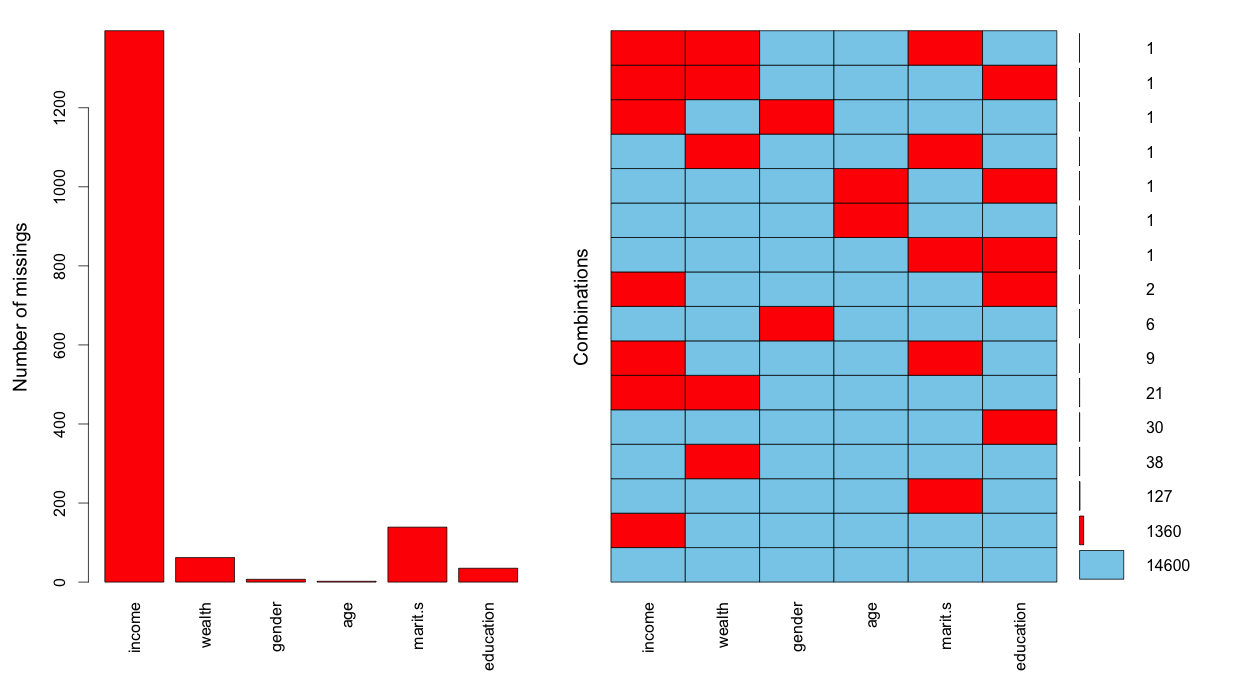
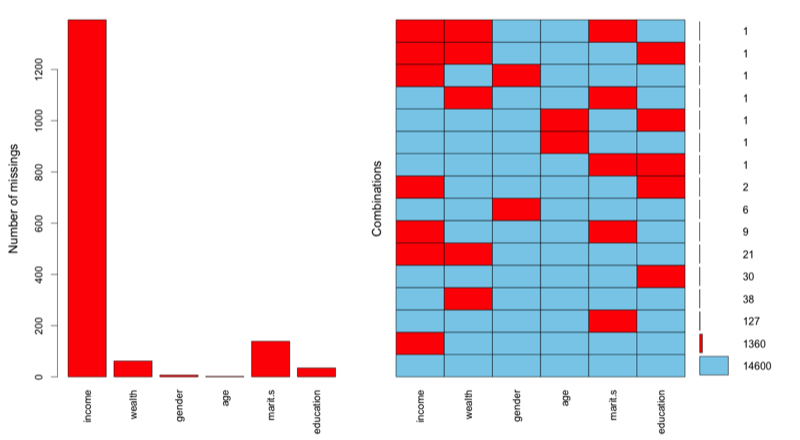
Методы обработки пропущенных значений Методы обработки пропущенных значений делят на традиционные и современные. К первым относят построчное и попарное удаление наблюдений, замещение средним и замещение с использованием регрессии. Ко вторым - замещение посредством оценки максимального правдоподобия, множественное замещение, селективную модель и модель смешанных паттернов. При построчном удалении из массива исключаются любые наблюдения, в значениях переменных которых присутствует хотя бы один пропуск. Такой подход может использоваться только при ПСП-допущении. Но даже в этом в такой ситуации его использование ведет к снижению статистической мощности. Как и при построчном удалении, попарное удаление подходит исключительно при ПСП-допущении. Попарное удаление заключается в том, что в каждом конкретном случае анализа из него удаляются только те наблюдения, в которых присутствует хотя бы один пропуск по релеватным для данного анализа переменным. Как и при построчном удалении, оно подходит исключительно при ПСП-допущении. При этом создается дополнительная проблема, заключающаяся в использовании отличающихся выборок в рамках проверки различных гипотез одного исследовательского проекта. Использование замещения пропущенных значений выборочным средним не рекомендуется в любом случае. Это связано с тем, что такой способ обработки пропусков ведет к смещенным оценкам (поскольку уменьшает дисперсию переменных и ковариацию между ними), независимо от используемого допущения. Исключением является оценка самого среднего значения. Замещение с использованием регрессии (вместо пропущенных используются предсказанные значения) имеет схожие с предыдущим способом проблемы. Так, получаемые значения попадают в один паттерн, отвечающий регрессионной прямой, что вносит смещение как в смысле дисперсии, так и в смысле ковариации. Частично эта проблема может быть решена посредством добавления случайных остаточных значений к предсказанным величинам. В целом же данный способ замещения подходит при СП-допущении [Peugh, Enders, 2004; Cheema, 2014]. Замещение посредством оценки максимального правдоподобия, представляет собой итерационный процесс, каждая итерация которого включает два этапа: 1) средние значения переменных и ковариационная матрица используются для расчета регрессионных уравнений, предсказывающих пропущенные значения; 2) полученный массив используется для расчета обновленных средних значений и ковариационной матрицы. Эти этапы повторяются до тех пор, пока средние значения и ковариационная матрица не перестанут изменяться. Можно сказать, что в данном случае используется последовательный подход. В случае множественного замещения создается набор альтернативных массивов данных (от пяти и более), в которых пропущенные значения замещаются предсказанными посредством регресии с добавлением случайного элемента. После этого средние значения переменных и ковариационные матрицы обобщаются с целью получения итогового оценки. Этот подход можно назвать конкуретным. Как замещение посредством максимального правдоподобия, так и множественное замещения подходят для ситуаций, в которых исследователь исходит из ПСП или СП-допущений. Для случаев, когда делается НП-допущение, предназначены селективная модель и модель смешанных паттернов. Селективная модель соединяет основное регрессионное уравнение с дополнительным регрессионным уравнением, предсказывающим вероятность ответов. Две части модели связываются посредством скоррелированных остатков (correlated residuals), и эта связь является механизмом с помощью которого корректируются смещения модели, связанные с пропусками. Модель смешанных паттернов предполагает формирование подгрупп наблюдений, в которых обнаруживаются одинаковые паттерны пропусков данных, с дальнейшей оценкой интересующих параметров в каждой подгруппе. После чего находится средне-взвешенная оценка этих параметров. В отличии от современных методов обработки пропущенных значений при ПСП или СП-допущениях, методы обработки при НП-допущении не получили достаточно широкого признания [Enders, 2010: p. 56-328]. Работа в R Обзор техник работы с пропущенными данными в R сделан в работе Роберта Кабакова [Кабаков, 2014: с. 472-498]. Здесь мы коснемся лишь некоторых из них. В качестве примера проанализируем пропуски в переменной про доход респондента. Прежде всего необходимо изучить структуру пропусков в соотношении с другими переменными массива (пол, возраст, семейный статус, образование, общая оценка материального состояния семьи). Для этого используем функцию md.pattern() библиотеки mice:
Первый столбец показывает общее количество наблюдений, соответствующих паттернам, представленным в строках под названиями переменных массива. Сами паттерны читаются следующим образом: нули говорят, что по этой переменной наблюдение имеет пропуск, единицы - пропуска нет. Завершающий столбец показывает общее количество пропусков у каждого такого наблюдения. Следовательно, 14600 наблюдений массива не имеет пропусков (под всеми переменными стоит единица, завершающий столбец равен нулю); 1360 наблюдений имеют пропуск по переменной «доход» (income) и т.д.. В последней строке показано общее количество пропусков по каждой переменной и общее количество пропусков по всему массиву (суммарное значение завершающего столбца). Альтернативным способом представления тех же самых данных является построение специальной диаграммы с помощью функции aggr() библиотеки VIM (см.рис.): aggr(na.data, prop=FALSE, numbers=TRUE)
Как видно основная часть пропусков содержится именно в переменной про доходы респондента. Вместе с тем, пропуски по этой переменной достаточно редко встречаются совместно с пропусками по другим переменным (если бы такие ситуации присутствовали, их следовало бы изучить дополнительно). Далее следует проверить, связно ли распределение пропусков для переменной о доходах с распределениями значений других переменных. Для этого создадим новую переменную, содержащую единицы для отсутствующих данных по переменной «income» и нули для наблюдений с ответами. Далее найдем силу связи между полученной переменной и другими переменными массива:
na.data$income.na <- abs(is.na(na.data$income))
round(cor(na.data[c(4,7)], use=«pairwise.complete.obs"),2)
age income.na
age 1.00 -0.17
income.na -0.17 1.00
special.table <- function(x) prop.table(table(x, na.data$income.na),1)
na.tables <- lapply(na.data[-c(1,4,7)], special.table)
for (i in c("wealth","gender","marit.s","education")) {
print(round(na.tables[[i]],2))
}
x 0 1
Злиденне 0.94 0.06
Бiдне 0.93 0.07
Середнє 0.90 0.10
Заможне 0.83 0.17
x 0 1
Чоловiча 0.91 0.09
Жiноча 0.92 0.08
x 0 1
Нiколи не був (-ла) у шлюбi 0.86 0.14
Перебуваю у шлюбi 0.91 0.09
Розлучений, розiйшовся 0.92 0.08
Вдiвець (вдова) 0.98 0.02
x
0 1
Початкова, неповна середня 0.94 0.06
Середня загальна 0.89 0.11
Середня спецiальна 0.91 0.09
Перша ступiнь вищої освiти 0.92 0.08
Повна вища освiта 0.92 0.08
Сначала кратко остановимся на синтаксисе. В первой строке с помощью логической функции is.na() возвращается истина (TRUE или T) для пропусков (конвертируются в единицы с помощью функции abs()) и ложь (FALSE или F) для имеющихся значений (конвертируются в нули), а результаты записываются в переменную «income.na». Во второй строке с помощью функции cor() подсчитывается коэффициент корреляции Пирсона для полученной переменной и возраста (rs = 0,17). Соответствующие результаты округляются с помощью функции round(). Далее создается специальная функция special.table(), предназначенная для построения таблиц сопряженности между переменной «income.na» и категориальными переменными массива. После этого с помощью функции lapply() создаются и записываются в список na.tables соответствующие таблицы. В завершении с помощью цикла for таблицы выводятся на консоль. Нами не случайно были выбраны таблицы сопряженности для категориальных переменных - они отчетливее показывают имеющуюся взаимосвязь по сравнению с коэффициентами, рассчитываемыми для табличных данных. Как видно, материальное состояние и семейный статус влияют на вероятность неответа на вопрос о доходах (можно было бы использовать критерий независимости хи-квадрат для проверки значимости, но на таких больших выборках он теряет свою информативность). Также существует слабая взаимосвязь между неответами и возрастом. Эти результаты предоставляют больше свидетельств для выбора СП, а не ПСП-допущения. Конечно же, в данном случае высока вероятность НП-допущения, поскольку речь идет о такой чувствительной теме как заработок (об этом говорит и соответствующая таблица сопряженности). Далее представлено только использование множественного замещения (на случай принятия СП-допущения), поскольку методы обработки пропусков при НП-допущении в R, как и в других статистических пакетах, не реализованы, а соответствующая задача в рамкаха данной статьи перед нами не стоит. Для демонстрации множественного замещения мы применили подход, реализованный в библиотеке mice. Он состоит из трех этапов: 1) с помощью функции mice() моделируется набор массивов для тех значений, которые пропущены (по умолчанию таких массивов пять); 2) с помощью функции with() к каждому из полученных на предыдущем этапе массивов, совмещенному с основным массивом, применяется необходимый статистический метод (например, линейная регрессия); 3) с помощью функции pool() объединяются результаты, полученные для каждого из массивов на предыдущем этапе. Далее приведен только соответствующий синтаксис без самих результатов (результатом в данном случае будет привычная сводка на основании линейной регрессии):
mice.data <- mice(na.data) fit <- with(mice.data, lm(income ~ wealth)) pooled <- pool(fit) summary(pooled)
В завершении необходимо сказать о реализации в R построчного и попарного удаления наблюдений из анализа, пригодных при принятии ПСП-допущения и небольшой доле самих пропусков (менее 10%). Построчное удаление можно выполнить с помощью функции complete.cases() или na.omit(): final.na.data <- na.data[complete.cases(na.data),] final.na.data <- na.omit(na.data)
Что касается попарного удаления, то возможность его использования обычно заложена в инструментарий самих функций. Например, чуть ранее в этой статье была использована следующая команда: cor(na.data[c(4,7)], use=«pairwise.complete.obs»)
В данном случае аргумент «use» отвечает за специфику обработки пропущенных значений, а его вариант «pairwise.complete.obs» обеспечивает попарное удаление. Соответственно, при необходимости осуществления попарного удаления пропусков в рамках использования конкретного статистического метода в R следует правильно сконфигурировать отвечающий за это аргумент. Для того, чтобы узнать как это сделать, следует обратиться к соответствующей документации. Литература: 1) Бослаф С. Статистика для всех. - М., 2015. - 586 с. 2) Newman D. Missing Data: Five Practical Guidelines // Organizational Research Methods. - 2014. - №4. - P. 372-411. 3) Rubin D. Inference and Missing Data // Biometrika. - 1976. - №3. - P. 581-592. 4) Peugh J., Enders C. Missing Data in Educational Research: A Review of Reporting Practices and Suggestions for Improvement // Review of Educational Research. - 2004. - №4. - P. 525-556. 5) Cheema J. A Review of Missing Data Handling Methods in Education Research // Review of Educational Research. - 2014. - №4. - P. 487-508. 6) Enders C. Applied Missing Data Analysis. - New York, London, 2010. - 377 p. 7) Кабаков Р. R в действии. - М., 2014. - 580 с.