Анализ вопросов с возможностью множественного выбора в R
30/03/17 22:10 Относится к категории: R | Анализ данных | Результаты исследований | Эмпирическая социология
В нашем последнем мониторинге (ИС НАНУ, 2016) есть такой вопрос:
По Вашему мнению, что сегодня объединяет людей в украинском обществе? (Отметьте все подходящие ответы)
Поскольку отмечать можно было все подходящие ответы, то детальный анализ не такой простой как может показаться на первый взгляд. Ну и решил я поковыряться в этом всем с помощью R. Сначала стал придумывать как добраться до всех комбинаций, существующих в данных… и в принципе добрался, но не могу сказать, что это мне очень сильно помогло. Но было забавно. Поэтому ниже в статье мои скромные скрипты, если вдруг кто-то решит таким же заниматься. Допускаю, что в определенных случаях они могут быть вполне полезными (например, при ограничениях на количество выбираемых альтернатив).
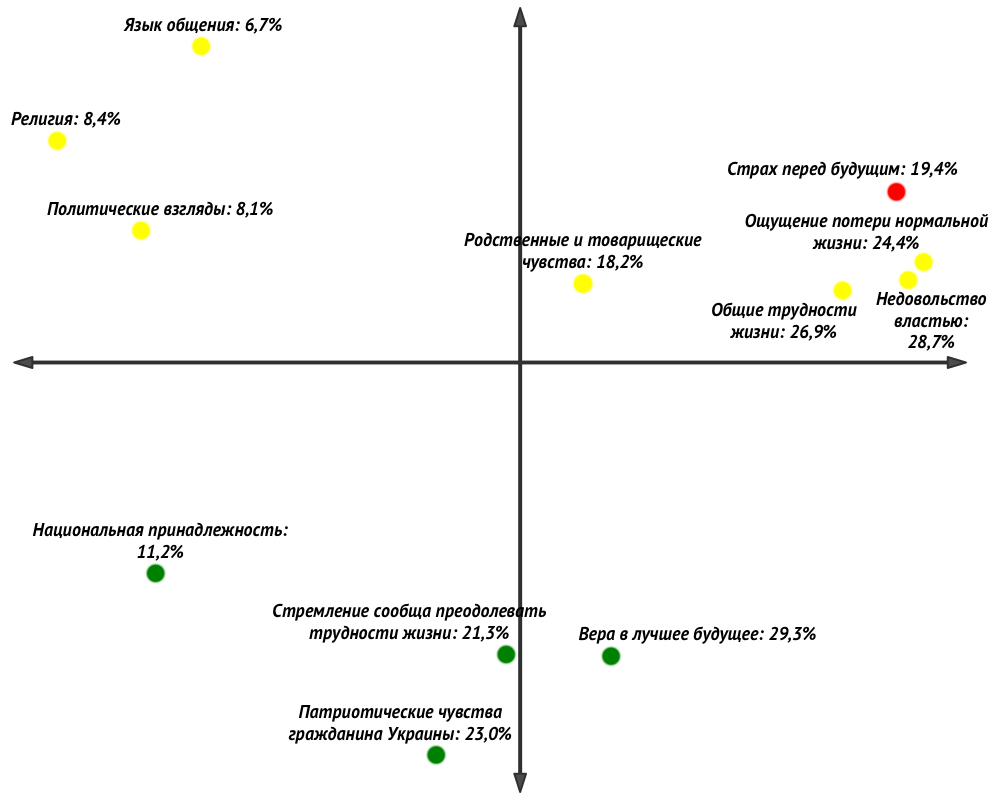
P.s. - когда я понял что ковыряние в имеющихся комбинациях не очень перспективно, то обратился к старому доброму многомерному шкалированию (эти команды тоже есть). Результат на рисунке. Проценты показывают как часто выбиралась альтернатива. Цвет точек показывает установки на гражданскую активность. Зеленые точки показывают мотивы, выбираемые респондентами, среди которых повышенная представленность установок на гражданскую активность, желтые – с обычной представленностью, красная – с пониженной представленностью. Интерпретации получаются весьма интересные =)
По Вашему мнению, что сегодня объединяет людей в украинском обществе? (Отметьте все подходящие ответы)
Поскольку отмечать можно было все подходящие ответы, то детальный анализ не такой простой как может показаться на первый взгляд. Ну и решил я поковыряться в этом всем с помощью R. Сначала стал придумывать как добраться до всех комбинаций, существующих в данных… и в принципе добрался, но не могу сказать, что это мне очень сильно помогло. Но было забавно. Поэтому ниже в статье мои скромные скрипты, если вдруг кто-то решит таким же заниматься. Допускаю, что в определенных случаях они могут быть вполне полезными (например, при ограничениях на количество выбираемых альтернатив).
P.s. - когда я понял что ковыряние в имеющихся комбинациях не очень перспективно, то обратился к старому доброму многомерному шкалированию (эти команды тоже есть). Результат на рисунке. Проценты показывают как часто выбиралась альтернатива. Цвет точек показывает установки на гражданскую активность. Зеленые точки показывают мотивы, выбираемые респондентами, среди которых повышенная представленность установок на гражданскую активность, желтые – с обычной представленностью, красная – с пониженной представленностью. Интерпретации получаются весьма интересные =)